
1. hotel 데이터셋
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
hotel_df = pd.read_csv('/content/drive/MyDrive/KDT/머신러닝과 딥러닝/data/hotel.csv')
hotel_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 119390 entries, 0 to 119389
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 119390 non-null object
1 is_canceled 119390 non-null int64
2 lead_time 119390 non-null int64
3 arrival_date_year 119390 non-null int64
4 arrival_date_month 119390 non-null object
5 arrival_date_week_number 119390 non-null int64
6 arrival_date_day_of_month 119390 non-null int64
7 stays_in_weekend_nights 119390 non-null int64
8 stays_in_week_nights 119390 non-null int64
9 adults 119390 non-null int64
10 children 119386 non-null float64
11 babies 119390 non-null int64
12 meal 119390 non-null object
13 country 118902 non-null object
14 distribution_channel 119390 non-null object
15 is_repeated_guest 119390 non-null int64
16 previous_cancellations 119390 non-null int64
17 previous_bookings_not_canceled 119390 non-null int64
18 reserved_room_type 119390 non-null object
19 assigned_room_type 119390 non-null object
20 booking_changes 119390 non-null int64
21 deposit_type 119390 non-null object
22 days_in_waiting_list 119390 non-null int64
23 customer_type 119390 non-null object
24 adr 119390 non-null float64
25 required_car_parking_spaces 119390 non-null int64
26 total_of_special_requests 119390 non-null int64
27 reservation_status_date 119390 non-null object
28 name 119390 non-null object
29 email 119390 non-null object
30 phone-number 119390 non-null object
31 credit_card 119390 non-null object
dtypes: float64(2), int64(16), object(14)
memory usage: 29.1+ MB- hotel: 호텔 종류
- is_canceled: 취소 여부
- lead_time: 예약 시점으로부터 체크인 될 때까지의 기간(얼마나 미리 예약했는지)
- arrival_date_year: 예약 연도
- arrival_date_month: 예약 월
- arrival_date_week_number: 예약 주
- arrival_date_day_of_month: 예약 일
- stays_in_weekend_nights: 주말을 끼고 얼마나 묶었는지
- stays_in_week_nights: 평일을 끼고 얼마나 묶었는지
- adults: 성인 인원수
- children: 어린이 인원수
- babies: 아기 인원수
- meal: 식사 형태
- country: 지역
- distribution_channel: 어떤 방식으로 예약했는지
- is_repeated_guest: 예약한적이 있는 고객인지
- previous_cancellations: 몇번 예약을 취소했었는지
- previous_bookings_not_canceled: 예약을 취소하지 않고 정상 숙박한 횟수
- reserved_room_type: 희망한 룸타입
- assigned_room_type: 실제 배정된 룸타입
- booking_changes: 예약 후 서비스가 몇번 변경되었는지
- deposit_type: 요금 납부 방식
- days_in_waiting_list: 예약을 위해 기다린 날짜
- customer_type: 고객 타입
- adr: 특정일에 높아지거나 낮아지는 가격
- required_car_parking_spaces: 주차공간을 요구했는지
- total_of_special_requests: 특별한 별도의 요청사항이 있는지
- reservation_status_date: 예약한 날짜
- name: 이름
- email: 이메일
- phone-number: 전화번호
- credit_card: 카드번호
# 데이터 분석에 필요 없는 열 삭제
hotel_df.drop(['reservation_status_date', 'name', 'email', 'phone-number', 'credit_card'], axis=1, inplace=True)hotel_df.describe()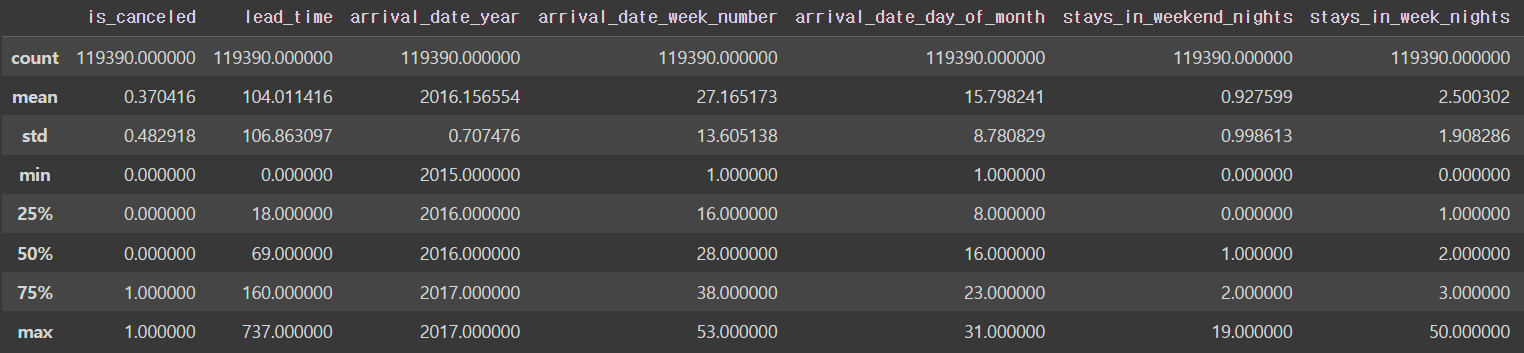

sns.displot(hotel_df['lead_time'])
sns.boxplot(hotel_df['lead_time'])
700일 이전 예약은 약간 이상치로 생각해 볼 수 있습니다.
sns.barplot(x=hotel_df['distribution_channel'], y=hotel_df['is_canceled'])
hotel_df['distribution_channel'].value_counts()
TA/TO 97870
Direct 14645
Corporate 6677
GDS 193
Undefined 5
Name: distribution_channel, dtype: int64sns.barplot(x=hotel_df['hotel'], y=hotel_df['is_canceled'])
sns.barplot(x=hotel_df['arrival_date_year'], y=hotel_df['is_canceled'])
plt.figure(figsize=(15,5))
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'])
월별 취소율은 월마다 차이가 있어보이지만, 월이 순서대로 정돈되지 않아 데이터를 깔끔하게 보기가 어렵습니다.
- 도표에 표출 순서 정렬하기
import calendar
print(calendar.month_name[1]) // January
print(calendar.month_name[2]) // February
print(calendar.month_name[3]) // Marchcalendar 모듈을 import 하면 month_name을 이용해 월의 이름을 순서대로 가져올 수 있습니다.
months = []
for i in range(1,13):
months.append(calendar.month_name[i])
months
['January',
'February',
'March',
'April',
'May',
'June',
'July',
'August',
'September',
'October',
'November',
'December']# order=months로 정렬
plt.figure(figsize = (15,5))
sns.barplot(x=hotel_df['arrival_date_month'],y=hotel_df['is_canceled'],order=months)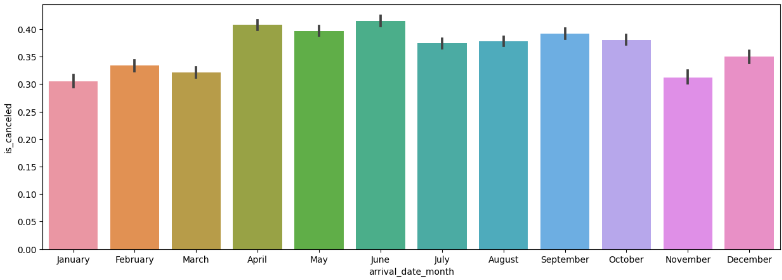
sns.barplot(x=hotel_df['is_repeated_guest'],y=hotel_df['is_canceled'])
sns.barplot(x=hotel_df['deposit_type'],y=hotel_df['is_canceled'])
hotel_df['deposit_type'].value_counts()
No Deposit 104641
Non Refund 14587
Refundable 162
Name: deposit_type, dtype: int64✔️ corr()함수 : corr() 함수는 Pandas 라이브러리에서 제공하는 데이터프레임(DataFrame)의 열들 간 상관계수를 계산하는 메서드입니다. 상관계수는 두 변수 간의 선형 관계의 강도와 방향을 나타내는 통계적 지표입니다. 상관계수는 일반적으로 -1부터 1까지의 범위를 가지며, 0에 가까울수록 두 변수 간의 상관관계가 없거나 매우 약합니다. -1은 두 변수가 반비례 관계에 있을 때를 나타내며, 1은 두 변수가 비례하는 관계에 있을 때를 나타냅니다. "pearson" (기본값), "kendall", "spearman" 중 하나를 선택하여 각각 피어슨, 켄달, 스피어만 상관계수를 계산할 수 있습니다.
plt.figure(figsize=(15,15))
sns.heatmap(hotel_df.corr(), cmap = 'coolwarm', vmax=1, vmin= -1, annot= True)

- 결측값 확인
hotel_df.isna().mean()
hotel 0.000000
is_canceled 0.000000
lead_time 0.000000
arrival_date_year 0.000000
arrival_date_month 0.000000
arrival_date_week_number 0.000000
arrival_date_day_of_month 0.000000
stays_in_weekend_nights 0.000000
stays_in_week_nights 0.000000
adults 0.000000
children 0.000034
babies 0.000000
meal 0.000000
country 0.004087
distribution_channel 0.000000
is_repeated_guest 0.000000
previous_cancellations 0.000000
previous_bookings_not_canceled 0.000000
reserved_room_type 0.000000
assigned_room_type 0.000000
booking_changes 0.000000
deposit_type 0.000000
days_in_waiting_list 0.000000
customer_type 0.000000
adr 0.000000
required_car_parking_spaces 0.000000
total_of_special_requests 0.000000
dtype: float64# NaN 비율이 워낙 작기때문에 과감하게 삭제
hotel_df= hotel_df.dropna()- 이상치 확인
hotel_df[hotel_df['adults']==0]
// 393 rows 확인hotel_df['people'] = hotel_df['adults']+hotel_df['children']+hotel_df['babies']
# 사람이 한명도 없는 데이터 삭제
hotel_df = hotel_df[hotel_df['people'] !=0 ]hotel_df['total_nights'] = hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']
hotel_df[hotel_df['total_nights']==0]
// 640 rows 확인숙박은 아니고 대실 개념일 수 있기 때문에 total_nights가 0인 컬럼은 그대로 둡니다.
hotel_df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 118728 entries, 0 to 119389
Data columns (total 30 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 118728 non-null object
1 is_canceled 118728 non-null int64
2 lead_time 118728 non-null int64
3 arrival_date_year 118728 non-null int64
4 arrival_date_month 118728 non-null object
5 arrival_date_week_number 118728 non-null int64
6 arrival_date_day_of_month 118728 non-null int64
7 stays_in_weekend_nights 118728 non-null int64
8 stays_in_week_nights 118728 non-null int64
9 adults 118728 non-null int64
10 children 118728 non-null float64
11 babies 118728 non-null int64
12 meal 118728 non-null object
13 country 118728 non-null object
14 distribution_channel 118728 non-null object
15 is_repeated_guest 118728 non-null int64
16 previous_cancellations 118728 non-null int64
17 previous_bookings_not_canceled 118728 non-null int64
18 reserved_room_type 118728 non-null object
19 assigned_room_type 118728 non-null object
20 booking_changes 118728 non-null int64
21 deposit_type 118728 non-null object
22 days_in_waiting_list 118728 non-null int64
23 customer_type 118728 non-null object
24 adr 118728 non-null float64
25 required_car_parking_spaces 118728 non-null int64
26 total_of_special_requests 118728 non-null int64
27 people 118728 non-null float64
28 total_nights 118728 non-null int64
29 season 118728 non-null object
dtypes: float64(3), int64(17), object(10)
memory usage: 28.1+ MB# season 파생변수 만들기
# arrival_date_month를 참고하여 생성
# 12, 1, 2 : winter / 3, 4, 5 : spring / 6, 7, 8 : summer / 9, 10, 11: fall
season_dic = {'spring': [3,4,5], 'summer': [6,7,8], 'fall': [9, 10, 11], 'winter': [12, 1, 2]}
new_season_dic = {}
for i in season_dic:
for j in season_dic[i]:
new_season_dic[calendar.month_name[j]]=i
new_season_dic
{'March': 'spring',
'April': 'spring',
'May': 'spring',
'June': 'summer',
'July': 'summer',
'August': 'summer',
'September': 'fall',
'October': 'fall',
'November': 'fall',
'December': 'winter',
'January': 'winter',
'February': 'winter'}# 딕셔너리 생성 후 map 함수 사용해서 한번에 적용
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
- 예약한 룸 타입(reserved_room_type)과 배정 받은 룸 타입(assigned_room_type)이 같으면 1, 다르면 0으로 표기하는 컬럼 생성하기
hotel_df['expected_room_type'] = (hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']).astype(int)# 이전에 예약 취소 횟수/ 정상 숙박횟수+취소 횟수로 취소율 구하기
hotel_df['cancel_rate'] = hotel_df['previous_cancellations'] / (hotel_df['previous_cancellations']+ hotel_df['previous_bookings_not_canceled'])hotel_df[hotel_df['cancel_rate'].isna()]
//109523 rows
hotel_df['cancel_rate'] = hotel_df['cancel_rate'].fillna(-1)
# 첫방문인 사람들은 별도의 카테고리컬한 숫자를 넣어줌.- 취소율의 결측값을 확인해보면, NaN값이 많은 것을 확인 해볼 수 있습니다. 이는 첫 방문자들의 취소율이 NaN 값으로 들어가 있기 때문입니다. 따라서 해당 NaN값은 카테고리컬한 값으로 채워줍니다.
✔ 숫자 -1을 사용하여 누락된 값을 나타내는 것은 일반적으로 "sentinel value" 또는 "flag value"를 사용하는 것입니다. 이는 특정한 목적을 나타내기 위해 선택된 특별한 카테고리컬한 값으로, 주로 데이터에서 누락된 값을 나타내거나 예외적인 상황을 표시하기 위해 사용됩니다.
- 구분 가능성: -1은 일반적인 데이터 값과 다르기 때문에 누락된 값을 쉽게 식별할 수 있습니다.
- 분석 편의성: 데이터를 처리하거나 시각화할 때 특별한 값을 사용하면 해당 값에 대한 특별한 조치를 취할 수 있습니다.
- 모델 학습: 몇몇 머신 러닝 모델은 NaN과 같은 누락된 값을 처리하는 데 어려움을 겪을 수 있습니다. 특별한 값을 사용하면 모델이 해당 값을 쉽게 이해하고 처리할 수 있습니다.
그러나 -1을 사용하는 것은 주관적인 선택일 뿐이며, 데이터의 특성과 분석 목적에 따라 다를 수 있습니다. 다른 값이나 다른 방법을 사용하는 것도 가능합니다. 중요한 것은 해당 값이 분석 결과에 어떤 영향을 미칠지 고려하는 것입니다.
hotel_df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 118728 entries, 0 to 119389
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 118728 non-null object
1 is_canceled 118728 non-null int64
2 lead_time 118728 non-null int64
3 arrival_date_year 118728 non-null int64
4 arrival_date_month 118728 non-null object
5 arrival_date_week_number 118728 non-null int64
6 arrival_date_day_of_month 118728 non-null int64
7 stays_in_weekend_nights 118728 non-null int64
8 stays_in_week_nights 118728 non-null int64
9 adults 118728 non-null int64
10 children 118728 non-null float64
11 babies 118728 non-null int64
12 meal 118728 non-null object
13 country 118728 non-null object
14 distribution_channel 118728 non-null object
15 is_repeated_guest 118728 non-null int64
16 previous_cancellations 118728 non-null int64
17 previous_bookings_not_canceled 118728 non-null int64
18 reserved_room_type 118728 non-null object
19 assigned_room_type 118728 non-null object
20 booking_changes 118728 non-null int64
21 deposit_type 118728 non-null object
22 days_in_waiting_list 118728 non-null int64
23 customer_type 118728 non-null object
24 adr 118728 non-null float64
25 required_car_parking_spaces 118728 non-null int64
26 total_of_special_requests 118728 non-null int64
27 people 118728 non-null float64
28 total_nights 118728 non-null int64
29 season 118728 non-null object
30 expected_room_type 118728 non-null int64
31 cancel_rate 118728 non-null float64
dtypes: float64(4), int64(18), object(10)
memory usage: 29.9+ MBhotel_df['country'].dtype // dtype('O')
# object 타입은 대문자'O'로 나타냄- Object 타입 확인해보기
obj_list = []
for i in hotel_df.columns:
if hotel_df[i].dtype == 'O':
obj_list.append(i)
obj_list
['hotel',
'arrival_date_month',
'meal',
'country',
'distribution_channel',
'reserved_room_type',
'assigned_room_type',
'deposit_type',
'customer_type',
'season']
hotel_df[obj_list].nunique()
hotel 2
arrival_date_month 12
meal 5
country 177
distribution_channel 5
reserved_room_type 9
assigned_room_type 11
deposit_type 3
customer_type 4
season 4
dtype: int64# 취소율과 관련 없어보이는 행 제거
hotel_df.drop(['country', 'meal'], axis=1, inplace = True)
obj_list.remove('country')
obj_list.remove('meal')
# 원 핫 인코딩
hotel_df = pd.get_dummies(hotel_df, columns = obj_list)
# hotel_df.columns => 72개



