앙상블은 여러 개별 모델을 결합하여 하나의 강력한 모델을 형성하는 기술입니다. 이는 각 모델의 약점을 서로 보완하고 강점을 결합하여 높은 정확도와 안정성을 달성하는 데 도움이 됩니다.
1. 보팅( Voting)
1-1. VotingClassifier
VotingClassifier는 여러 개의 서로 다른 머신러닝 분류기(Classifier)를 결합하여 하나의 강력한 앙상블 모델을 만드는 데 사용되는 Scikit-learn 라이브러리의 클래스입니다. 이는 앙상블 학습의 일종으로, 다양한 분류기의 예측을 조합하여 높은 정확도를 달성하려는 목적으로 사용됩니다.
- Hard Voting:
- Hard Voting은 다수결 원칙을 기반으로 합니다. 즉, 각 분류기가 투표를 하고, 다수의 분류기가 선택한 클래스를 최종 예측 결과로 선택합니다.
- 이 방법은 각 분류기의 예측이 클래스 레이블 형태로 이루어져야 합니다.
- Soft Voting:
- Soft Voting은 각 분류기의 예측에 대한 확률을 평균하여 가장 높은 평균 확률을 가진 클래스를 최종 예측 결과로 선택합니다.
- 이 방법은 각 분류기가 클래스의 확률을 제공할 수 있을 때 사용됩니다.
예) 로지스틱 회귀, 의사결정 트리, 서포트 벡터 머신(SVM)을 사용하여 VotingClassifier만들기
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 분류기 생성
clf1 = LogisticRegression(random_state=1)
clf2 = DecisionTreeClassifier(random_state=1)
clf3 = SVC(probability=True, random_state=1)
# VotingClassifier 생성
voting_clf = VotingClassifier(estimators=[('lr', clf1), ('dt', clf2), ('svc', clf3)], voting='soft')
# 데이터 생성
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_clusters_per_class=2, random_state=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 모델 훈련 및 예측
voting_clf.fit(X_train, y_train)
y_pred = voting_clf.predict(X_test)
# 정확도 출력
print("Accuracy:", accuracy_score(y_test, y_pred))1-2. VotingRegressor
VotingRegressor는 Scikit-learn 라이브러리에서 제공되는 회귀(Regression) 모델들을 결합하여 하나의 강력한 앙상블 회귀 모델을 생성하는 클래스입니다. VotingRegressor는 기본적으로 각 모델의 예측값을 평균하여 최종 예측값을 생성합니다. 이는 회귀 문제에서 사용되는 앙상블 기법 중 하나로, 다양한 모델의 다양한 관점을 결합하여 개별 모델의 약점을 보완하고 높은 예측 성능을 달성하는 데 사용됩니다.
예) 선형 회귀(Linear Regression), 의사결정 트리 회귀(DecisionTreeRegressor), 랜덤 포레스트 회귀(RandomForestRegressor)를 사용하여 VotingRegressor를 만드는 예제
from sklearn.ensemble import VotingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 회귀 모델 생성
regressor1 = LinearRegression()
regressor2 = DecisionTreeRegressor()
regressor3 = RandomForestRegressor()
# VotingRegressor 생성
voting_regressor = VotingRegressor(estimators=[('lr', regressor1), ('dt', regressor2), ('rf', regressor3)])
# 데이터 생성
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 모델 훈련 및 예측
voting_regressor.fit(X_train, y_train)
y_pred = voting_regressor.predict(X_test)
# 평균 제곱 오차(MSE) 출력
print("Mean Squared Error:", mean_squared_error(y_test, y_pred))2. 배깅(bagging)
앙상블 알고리즘에서 배깅(bagging) 방법은 여러 개의 랜덤한 학습 데이터 부분 집합에서 기본 학습 모델을 여러 번 만들어, 그들의 개별 예측을 종합하여 최종 예측을 형성하는 알고리즘 중 하나입니다. 이러한 방법들은 기본 모델(예: 의사결정 트리)의 분산을 줄이기 위한 것으로, 그 구성 과정에 무작위성을 도입하고 이를 앙상블화(예: 랜덤 포레스트)하여 성능을 향상시키는 데 사용됩니다. Bagging은 복원(Replacement)을 허용하여 샘플을 복원해서 다시 선택하는 방법을 사용합니다. 부트스트랩 샘플링이라고도 불리는 이 방법은 데이터셋으로부터 중복을 포함한 무작위한 샘플 부분 집합을 만들어 각 모델을 학습시키는데 사용됩니다. 이런 경우에 배깅 방법은 기본 알고리즘을 수정하지 않고도 단일 모델에 비해 성능을 간단히 향상시킬 수 있습니다. ( 과적합을 감소시키는 방법으로써, 강하고 복잡한 모델(예: 완전히 발전된 의사결정 트리)과 가장 잘 작동하는 특징을 갖습니다. 이는 일반적으로 부스팅 방법이 약한 모델(예: 얕은 의사결정 트리)과 가장 잘 작동하는 것과 대조됩니다.)
배깅 방법은 여러 가지 형태로 나타날 수 있지만, 주로 학습 데이터 집합에서 무작위로 추출하는 방법에 따라 차이가 있습니다.
랜덤 포레스트
1. 랜덤 포레스트 랜덤 포레스트는 머신러닝에서 널리 사용되는 앙상블 기법 중 하나로, 주로 배깅(Bagging) 방법을 기반으로 합니다. https://junyealim.tistory.com/90 앙상블 모델 앙상블은 여러 개별 모
junyealim.tistory.com
3. 부스팅 (Boosting)
부스팅(Boosting)은 약한 학습자(weak learner)들을 결합하여 강한 학습자(strong learner)를 만드는 앙상블 학습 기법입니다. 약한 학습자란 모델이 무작위 추측보다 약간 더 나은 예측을 할 수 있는 수준입니다. 예를 들면, 얕은 의사결정 트리나 선형 모델이 많이 사용됩니다. 각 모델은 이전 모델이 잘못 예측한 샘플에 가중치를 부여하여 다음 모델이 이를 보완하는 순차적인 방식으로 학습합니다. 이는 여러 개의 약한 예측 모델들을 조합하여 높은 정확도와 예측 성능을 갖는 모델을 생성하는데 사용됩니다. 일반적으로 예측을 조합하는데 가중 평균이나 투표 방식을 사용합니다. 부스팅에는 다양한 변형이 있습니다. 예를 들어, AdaBoost는 오차에 대한 가중치를 조절하면서 순차적으로 학습하는 방식을 사용하며, Gradient Boosting은 그래디언트(오차의 기울기)를 활용하여 학습합니다.
3-1. 그래디언트 부스팅(Gradient Boosting)
그래디언트 부스팅은 이전 모델의 예측과 실제 값 간의 오차에 대한 그래디언트(기울기)를 계산하여 다음 모델을 학습시킵니다. 쉽게 말해, Gradient Boosting Machine (GBM)에서 각 예측기(예: 결정 트리)는 이전 예측기가 만든 잔여 오차를 학습하려고 합니다.
다음은 GBM의 작동 원리를 간단히 설명한 것입니다:
- 첫 번째 예측기: 초기 모델이 데이터를 예측합니다.
- 잔여 오차 계산: 이전 예측과 실제 값 사이의 차이를 계산하여 잔여 오차를 얻습니다.
- 두 번째 예측기 학습: 두 번째 예측기는 이 잔여 오차를 예측하도록 학습합니다.
- 누적 예측: 첫 번째 예측기의 예측과 두 번째 예측기의 예측을 더하여 더 나은 예측을 만듭니다.
- 잔여 오차 업데이트: 실제 값과 현재까지의 예측값 간의 차이를 계산하여 새로운 잔여 오차를 얻습니다.
- 다음 예측기 학습: 다음 예측기는 새로운 잔여 오차를 예측하도록 학습합니다.
GBM은 가중치 업데이트를 경사하강법(Gradient Descent) 기법을 사용하여 최적화된 결과를 얻는 알고리즘입니다. 따라서 과적합 이슈가 있습니다.
예) scikit-learn에 내장된 기본 GradientBoostingClassifier 사용해보기
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# iris(붓꽃) 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Gradient Boosting 분류기 생성
gradient_boost_clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# 모델 훈련
gradient_boost_clf.fit(X_train, y_train)
# 테스트 데이터로 예측
y_pred = gradient_boost_clf.predict(X_test)
# 정확도 출력
accuracy = accuracy_score(y_test, y_pred)
print(f'Gradient Boosting 정확도: {accuracy:.2f}')
// Gradient Boosting 정확도: 1.00- XGBoost : XGBoost는 GBM과 마찬가지로 경사하강법 기법을 사용합니다. 하지만 XGBoost는 GBM의 단점인 느린 수행 시간과 과적합 규제(Regularization) 부재 등의 문제를 해결해서 매우 주목을 받고 있습니다. XGBoost는 정규화를 위한 추가적인 항들을 포함하여 모델의 복잡성을 제어할 수 있습니다. 이는 트리의 깊이, 각 트리의 가중치, 잎 노드의 최소 자식 수 등을 포함합니다. 또한 GBM은 일반적으로 트리 분할 방법으로 깊이 우선 탐색을 따릅니다. 각 노드에서 최적의 분할을 찾기 위해 해당 노드의 하위 트리로 재귀적으로 이동합니다. 즉 한가지 경로를 끝까지 탐색 후 다음 경로로 이동하여 트리를 최대한 깊에 파고들어 나아가는 방식입니다. 그에 반해 XGBoost의 기본적인 트리 분할 방법은 균형 트리 분할을 따릅니다. 각 레벨에서 모든 노드를 평가하고 다음 레벨로 이동하며 최적의 분할을 찾습니다. XGBoost는 분류 및 회귀 문제에 모두 사용할 수 있으며 특히 대용량 데이터셋에 적합합니다.
- LightGBM: LightGBM은 Microsoft에서 개발한 그래디언트 부스팅 알고리즘입니다. XGBoost와 마찬가지로 트리 기반 앙상블 학습 방법을 사용하지만, XGBoost의 경우 균형 트리 분할(Level Wise) 방식을 사용했다면, LightGBM은 리프 중심 트리 분할(Leaf Wise) 방식을 사용합니다. Leaf Wise은 트리의 균형을 맞추지 않고 최대 손실 값(Max data loss)를 가지는 leaf 노드를 지속적으로 분할하면서 Tree의 깊이(depth)가 깊어지고 비대칭적인 트리가 생성 됩니다. 균형 트리 분할(Lever wise) 방식보다 예측 오류 손실을 최소화 할 수 있습니다.적은 데이터 세트의 적용을 할 경우 과적합 가능성이 큽니다.(일반적으로 적은 데이터 세트의 기준은 공식 문서에서 10,000건 이하로 정의)
3-2. 에이다 부스팅( AdaBoost)
AdaBoost의 핵심 원리는 데이터의 수정된 버전에 대해 약한 학습기(작은 결정 트리)를 반복해서 적합시키는 것입니다. 이들의 예측은 가중치가 부여된 과반수 투표(또는 합산)를 통해 최종 예측을 생성합니다. 각각의 부스팅 반복에서 데이터 수정은 각 훈련 샘플에 가중치를 적용하는 것으로 이루어집니다. 첫 번째 단계에서는 원래 데이터에 대해 약한 학습기를 훈련시킵니다. 나아가면서 이전 단계에서 유도된 부스팅 모델에 의해 잘못 예측된 훈련 예제의 가중치가 증가하고, 올바르게 예측된 경우 가중치가 감소합니다. 샘플 가중치는 개별적으로 수정되고 학습 알고리즘이 수정된 가중치 데이터에 다시 적용됩니다. 반복이 진행됨에 따라 예측이 어려운 예제들은 점점 영향력을 받게 됩니다. 이로 인해 각각의 이후 약한 학습기는 이전 학습기에서 놓친 예제에 집중하게 됩니다.
AdaBoost는 분류와 회귀 문제 모두에 사용할 수 있습니다.
다중 클래스 분류를 위해 AdaBoostClassifier는 AdaBoost-SAMME와 AdaBoost-SAMME.R을 구현하고, 회귀를 위해 AdaBoostRegressor는 AdaBoost.R2를 구현합니다.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 가상의 데이터 생성
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 약한 학습기로서 결정 스텀프 사용
base_estimator = DecisionTreeClassifier(max_depth=1)
# AdaBoost 분류기 생성
adaboost_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, random_state=42)
# 모델 훈련
adaboost_clf.fit(X_train, y_train)
# 테스트 데이터로 예측
y_pred = adaboost_clf.predict(X_test)
# 정확도 출력
accuracy = accuracy_score(y_test, y_pred)
print(f'AdaBoost 정확도: {accuracy:.2f}')
// AdaBoost 정확도: 0.874. 스테킹
스태킹(Stacking)은 여러 개의 다른 모델(개별 추정기)의 예측 결과를 결합하여 더 정확한 예측을 수행하는 앙상블 학습 방법입니다. 스태킹은 모델 간의 계층 구조를 형성하여 작동합니다.
스태킹은 일반적으로 두 단계로 이루어집니다. 첫 번째 단계에서는 원본 데이터를 사용하여 여러 개의 다른 모델을 학습시킵니다. 이러한 모델은 서로 다른 알고리즘으로 구성될 수도 있고, 같은 알고리즘의 다른 설정으로 구성될 수도 있습니다.
두 번째 단계에서는 첫 번째 단계에서 학습된 모델의 예측 결과를 새로운 특성(feature)으로 사용하여 최종 모델을 학습시킵니다. 이 최종 모델은 보통 단순한 모델(예: 선형 회귀)로 구성되며, 첫 번째 단계에서 나온 예측 결과를 입력으로 받아 최종 예측을 수행합니다.
스태킹은 여러 모델의 예측 결과를 결합함으로써, 각 모델의 장점을 활용하고 편향을 감소시킬 수 있습니다. 또한, 스태킹은 다양한 모델의 다양한 관점을 종합하여 더 강력한 예측 모델을 구축하는 데 도움이 될 수 있습니다.
Stacking에서 여러 다른 모델의 출력값을 다음 단계에서 합치는 일반적인 방법은 각 모델의 예측 값을 새로운 특성으로 추가하는 것입니다. 즉, 각 모델이 생성한 예측 값을 새로운 열로 추가하여 데이터를 확장합니다.
- 각 모델을 개별적으로 학습하고 예측하는 과정을 명시적으로 제어할 수 있습니다.
- 데이터 전처리 및 각 모델의 예측값을 스택하는 부분이 직관적이며 세부 조정이 쉽습니다.
- Stacking의 장점 중 하나인 모든 모델을 통합적으로 학습하는 기능이 부족합니다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import StackingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
# 예시 데이터 생성
X, y = np.random.rand(100, 5), np.random.rand(100)
# 데이터를 훈련 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 여러 모델 정의
model1 = RandomForestRegressor()
model2 = LinearRegression()
# 각 모델에 대한 예측값 생성
pred1 = model1.fit(X_train, y_train).predict(X_test)
pred2 = model2.fit(X_train, y_train).predict(X_test)
# 각 모델의 예측값을 데이터에 추가
X_train_stacked = np.column_stack((X_train, pred1, pred2))
X_test_stacked = np.column_stack((X_test, pred1, pred2))
# 최종 모델 정의
final_model = LinearRegression()
# 최종 모델 학습
final_model.fit(X_train_stacked, y_train)
# 최종 모델을 사용하여 예측
final_pred = final_model.predict(X_test_stacked)
# 최종 모델의 성능 평가
mse = mean_squared_error(y_test, final_pred)
print(f'Mean Squared Error: {mse}')
혹은 StackingRegressor를 파이프라인(pipeline) 으로 사용해서 이전 단계의 학습 결과를 다음 단계에서 데이터로 사용할 수 있습니다. 파이프라인은 여러 단계를 순차적으로 처리하며 각 단계에서의 변환 및 모델 학습을 연결하여 처리합니다.
- StackingRegressor를 사용하면 개별 모델과 최종 모델을 통합적으로 학습할 수 있습니다.
- 각 모델의 예측값을 생성하고 스택하는 부분이 내부적으로 처리되므로 코드가 간결합니다.
- 개별 모델의 학습 및 예측을 개별적으로 제어하기 어렵습니다.
- 내부적으로 처리되는 부분이 많아 세부 조정이 제한될 수 있습니다.
from sklearn.datasets import make_regression
from sklearn.ensemble import StackingRegressor, RandomForestRegressor, GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
# 예시 데이터 생성
X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
# 데이터를 훈련 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 개별 모델 정의
base_models = [
('rf', make_pipeline(StandardScaler(), RandomForestRegressor(random_state=42))),
('gb', make_pipeline(StandardScaler(), GradientBoostingRegressor(random_state=42)))
]
# 최종 모델 정의 (Linear Regression)
final_model = LinearRegression()
# StackingRegressor 파이프라인 생성
stacking_model = StackingRegressor(estimators=base_models, final_estimator=final_model)
# Stacking 모델 학습
stacking_model.fit(X_train, y_train)
# 테스트 데이터에 대한 예측
y_pred = stacking_model.predict(X_test)
# 성능 평가
mse = mean_squared_error(y_test, y_pred)
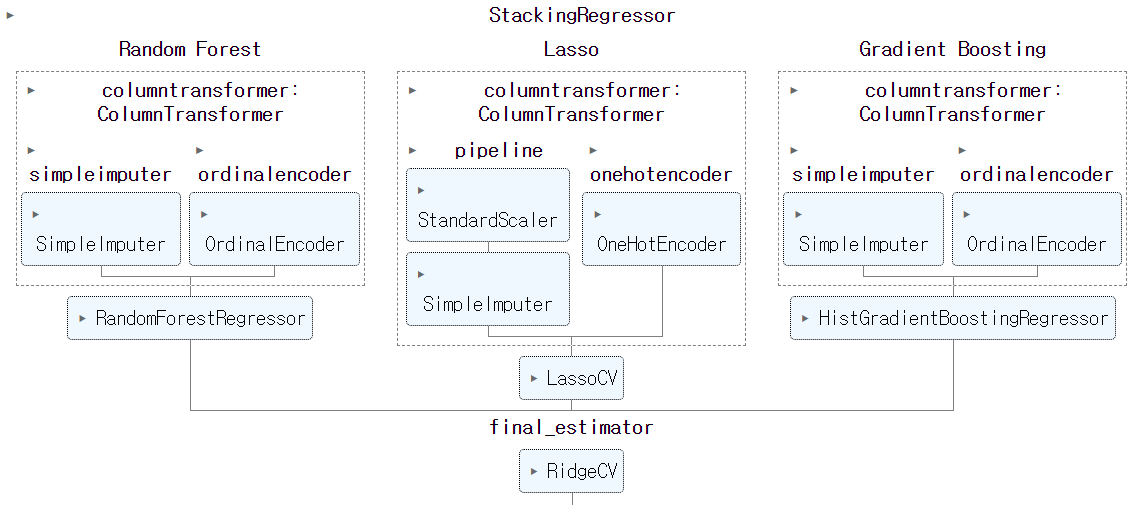
print(f'Mean Squared Error: {mse}')https://scikit-learn.org/stable/auto_examples/ensemble/plot_stack_predictors.html
Combine predictors using stacking
Stacking refers to a method to blend estimators. In this strategy, some estimators are individually fitted on some training data while a final estimator is trained using the stacked predictions of ...
scikit-learn.org
- 약한 학습기(Weak Learner): 결정 스텀프(decision stump)와 같이 간단한 모델을 약한 학습기라고 합니다. 결정 스텀프는 하나의 특성만을 사용하여 데이터를 분류하는 깊이가 1인 간단한 결정 트리입니다. 작은 결정 나무 (Small Decision Tree)역시 깊이나 리프 노드의 수 등이 제한된 결정 트리로 규모가 큰 결정 트리에 비해 간단한 모델이며 약한 학습기로서 사용될 수 있습니다.
- 경사 하강법(Gradient Descent): 이 알고리즘은 함수의 기울기(경사)를 사용하여 현재 위치에서의 최솟값을 찾아가는 최적화 알고리즘 중 하나입니다. 기본 아이디어는 현재 위치에서의 기울기를 계산하고, 기울기가 감소하는 방향으로 이동하여 최적점을 찾아가는 것입니다. 학습률은 각 단계에서 얼마나 큰 폭으로 이동할지를 결정하는 하이퍼파라미터입니다. 경사 하강법의 성능은 학습률(learning rate)에 크게 의존하며, 이 값이 적절하지 않으면 수렴이 느려지거나 발산할 수 있습니다.



