
1. 랜덤 포레스트
랜덤 포레스트는 머신러닝에서 널리 사용되는 앙상블 기법 중 하나로, 주로 배깅(Bagging) 방법을 기반으로 합니다.
https://junyealim.tistory.com/90
앙상블 모델
앙상블은 여러 개별 모델을 결합하여 하나의 강력한 모델을 형성하는 기술입니다. 이는 각 모델의 약점을 서로 보완하고 강점을 결합하여 높은 정확도와 안정성을 달성하는 데 도움이 됩니다. 1
junyealim.tistory.com
랜덤 포레스트는 각 결정 나무를 구성할 때, 학습 데이터에서 랜덤하게 샘플을 추출하여 사용하고, 각 노드에서 최적의 분할을 찾을 때 특정 변수들을 랜덤하게 선택합니다. 이러한 랜덤성은 모델의 다양성을 증가시켜 오버피팅을 방지하고, 전반적인 일반화 성능을 향상시킵니다. 개별 결정 나무보다는 과적합(overfitting)을 완화하지만 데이터가 너무 작거나 불균형한 경우에는 주의가 필요합니다.
종합하면, 랜덤 포레스트는 머신러닝에서 신뢰성 높은 모델을 만들기 위한 강력한 도구로 자리매김하고 있지만 오버피팅을 주의해야합니다. 따라서 적절한 파라미터 조정과 데이터에 대한 이해를 통해 최적의 성능을 발휘해야 합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(hotel_df.drop('is_canceled', axis = 1), hotel_df['is_canceled'], test_size = 0.3, random_state=2023)
X_train.shape, y_train.shape // ((83109, 71), (83109,))
X_test.shape, y_test.shape // ((35619, 71), (35619,))from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
pred1 = rf.predict(X_test)
pred1 // array([0, 0, 0, ..., 1, 0, 1])- predict_proba : 입력 데이터가 각 클래스에 속할 확률을 나타내는 배열을 반환합니다. 이진 분류의 경우, 반환된 배열은 두 개의 열로 구성되어 있으며 첫 번째 열은 클래스 0에 속할 확률을, 두 번째 열은 클래스 1에 속할 확률을 나타냅니다.
proba1 = rf.predict_proba(X_test) # model.predict_proba(입력 데이터)
proba1
array([[1. , 0. ],
[0.92 , 0.08 ],
[0.93 , 0.07 ],
...,
[0.31 , 0.69 ],
[0.93 , 0.07 ],
[0.24937638, 0.75062362]])
# 첫번째 테스트 데이터에 대한 예측 결과
proba1[0] // array([1., 0.]) >> 취소할 확률이 없다고 예측함
# 모든 테스트 데이터에 대한 호텔 예약을 취소할 확률만 출력
proba1[:,1]
array([0. , 0.08 , 0.07 , ..., 0.69 , 0.07 ,
0.75062362])2. 머신러닝, 딥러닝에서 모델의 성능을 평가하는데 사용하는 측정값
머신러닝과 딥러닝 모델의 성능 평가에 사용되는 다양한 지표들이 있습니다. 이러한 지표들은 모델이 얼마나 잘 예측하는지를 평가하고, 모델의 강점과 약점을 파악하는 데 도움을 줍니다.
- Accuracy(정확도) : 모델이 올바르게 예측한 비율. 모든 예측 중에서 올바르게 예측한 비율을 측정하는 주요 지표.
- Precision(정밀도) : 모델이 긍정으로 예측한 것 중에서 실제로 긍정인 비율.
- Recall(재현율) : 실제 긍정 중에서 모델이 긍정으로 예측한 비율.
- F1 Score : 정밀도와 재현율의 조화 평균. 정밀도와 재현율 간의 균형을 맞추기 위한 종합적인 성능 지표.
- AUC-ROC Curve(Area Under the Receiver Operating Characteristic) : ROC Curve 아래의 면적을 나타내는 값. 참 양성률과 가양성률 간의 균형을 측정하여 이진 분류 모델의 성능을 평가.
- ROC Curve: 이진 분류 모델의 성능을 시각적으로 나타내는 곡선. 모델의 임계값 변화에 따른 성능 변화를 확인하며, 모델의 분류 능력을 시각적으로 평가.
- AUC (Area Under the Curve): ROC 커브와 직선 사이의 면적. 범위는 0.5~1이며 값이 클수록 모델의 성능이 좋음. 이진 분류의 정확도를 나타내는 중요한 지표 중 하나. https://bioinformaticsandme.tistory.com/328
AUC-ROC 커브
AUC-ROC 커브 StartBioinformaticsAndMe 1. AUC - ROC Curve?: AUC-ROC 곡선은 다양한 임계값에서 모델의 분류 성능에 대한 측정 그래프임*ROC(Receiver Operating Characteristic) = 모든 임계값에서 분류 모델의 성능을 보여
bioinformaticsandme.tistory.com
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score
# 정확도
accuracy_score(y_test, pred1) // 0.8597097054942587
# 혼돈행렬
confusion_matrix(y_test, pred1)
array([[20820, 1615],
[ 3382, 9802]])print(classification_report(y_test, pred1))
precision recall f1-score support
0 0.86 0.93 0.89 22435
1 0.86 0.74 0.80 13184
accuracy 0.86 35619
macro avg 0.86 0.84 0.84 35619
weighted avg 0.86 0.86 0.86 35619✔️support : 각 클래스에 대한 실제 샘플 수
roc_auc_score(y_test, proba1[:, 1])
// 0.9266582306409454
# 하이퍼 파라미터 수정(max_depth = 30을 적용)
rf2 = RandomForestClassifier(max_depth=30, random_state = 2023)
rf2.fit(X_train, y_train)
proba2 = rf2.predict_proba(X_test)
roc_auc_score(y_test,proba2[:, 1])
// 0.9282014901868613
# 하이퍼 파라미터 적용 전 - 적용 후
0.9259007937033847 - 0.9282014901868613
// -0.0023006964834765276 미세하게 좋아짐import matplotlib.pyplot as plt
from sklearn.metrics._plot.roc_curve import roc_curve
fpr, tpr, thr = roc_curve(y_test, proba2[:,1])
print(fpr, tpr, thr)
[0. 0. 0. ... 0.93572543 0.93577 1. ]
[0. 0.35618932 0.35702367 ... 0.99886226 0.99886226 1. ]
[2.00000000e+00 1.00000000e+00 9.99523810e-01 ... 6.41025641e-05 4.27350427e-05 0.00000000e+00]이 함수를 호출하면 다음과 같은 세 가지 배열이 반환됩니다.
- fpr (False Positive Rate): 거짓 양성률, 즉 실제 음성 중에서 모델이 양성으로 잘못 예측한 비율을 나타냅니다.
- tpr (True Positive Rate): 참 양성률, 즉 실제 양성 중에서 모델이 정확하게 양성으로 예측한 비율을 나타냅니다.
- thr (Thresholds): 모델의 결정 경계(thresholds)에 대한 배열입니다. 결정 경계(Decision Boundary)는 모델이 예측을 만들기 위해 클래스를 나누는 경계를 나타냅니다. ROC 커브는 다양한 결정 경계에서의 TPR과 FPR을 시각화하기 위해 사용되므로, 각 결정 경계에 대한 정보도 반환됩니다.
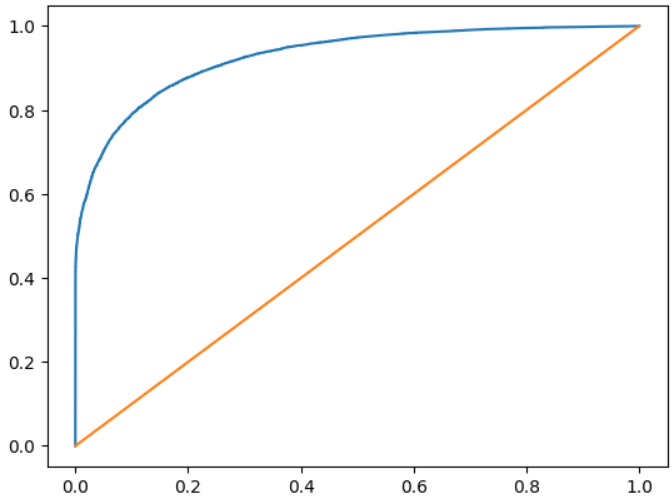
plt.plot(fpr,tpr,label = 'ROC Curve')
plt.plot([0,1], [0,1])
plt.show()plt.plot([0, 1], [0, 1]) 을 해주는 이유는 대각선으로 그어진 직선이 랜덤한 분류 모델의 성능을 나타내기 때문에 비교를 더 눈에 쉽게 보여주기 위함입니다.
# 하이퍼 파라미터 수정(max_depth = 50을 적용)
rf3 = RandomForestClassifier(max_depth=50, random_state = 2023)
rf3.fit(X_train, y_train)
proba3 = rf3.predict_proba(X_test)
roc_auc_score(y_test,proba3[:, 1])
// 0.9266842801399297
# 하이퍼 파라미터 수정(min_samples_split = 5을 적용)
rf4 = RandomForestClassifier(min_samples_split = 5, random_state = 2023)
rf4.fit(X_train, y_train)
proba4 = rf4.predict_proba(X_test)
roc_auc_score(y_test,proba4[:, 1])
// 0.92673261962552013. 하이퍼 파라미터 최적의 값을 찾는 방법
- GridSearchCV:
- 정의: GridSearchCV는 가능한 모든 하이퍼파라미터 조합을 시도하여 최적의 조합을 찾는 탐색 방법입니다.
- 동작 방식: 탐색할 하이퍼파라미터 값들을 그리드(Grid)처럼 미리 정의하고, 각각의 조합에 대해 교차 검증을 수행하여 최적의 성능을 내는 조합을 선택합니다.
- 장점: 전체 탐색 공간을 다루기 때문에 최적의 조합을 찾을 수 있습니다.
- 단점: 계산 비용이 높고, 모든 조합을 시도하기 때문에 수행 시간이 길어질 수 있습니다.
- RandomizedSearchCV:
- 정의: RandomizedSearchCV는 무작위로 선택한 하이퍼파라미터 값들을 사용하여 최적의 조합을 찾는 방법입니다.
- 동작 방식: 무작위로 지정된 하이퍼파라미터 값들 중에서 사용자가 정한 횟수(n_iter)만큼 조합을 선택하여 교차 검증을 수행합니다.
- 장점: 계산 비용이 상대적으로 낮고, 무작위 탐색으로도 좋은 성능의 조합을 찾을 수 있습니다.
- 단점: 최적의 조합을 놓칠 수 있으며, 반복 수행 시마다 서로 다른 결과를 얻을 수 있습니다.
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
params = {
'max_depth': [ None, 10, 30, 50],
'min_samples_split' : [ 2, 3, 5, 7, 10]
}
rf6 = RandomForestClassifier(random_state = 2023)
grid_df = GridSearchCV(rf6, params, cv = 5 )
# params에 옵션이 많으면 그만큼 시간이 오래 걸린다.
# cv: 데이터 교차검증 (안써주면 cv = 5 기본값으로 진행)
grid_df.fit(X_train, y_train)
grid_df.best_params_
// {'max_depth': 50, 'min_samples_split': 3}
# n_iter 적용. 랜덤으로 돌릴 횟수를 정함.
rf8 = RandomForestClassifier(random_state = 2023)
rand_df = RandomizedSearchCV(rf8, params, n_iter=10, random_state = 2023 )
# n_iter=10 : 20개 조합중에 랜덤으로 10개만 돌리겠다
rand_df.fit(X_train, y_train)
rand_df.cv_results_ : 조합 과정과 진행 결과를 볼 수 있음.
rand_df.cv_results_
{'mean_fit_time': array([13.02924705, 12.25790462, 13.60862794, 11.63070927, 11.9080307 ,
11.75771642, 6.10767241, 12.14381194, 14.39633331, 6.06477933]),
'std_fit_time': array([0.99746247, 0.42569393, 0.98047479, 0.4215285 , 0.38402879,
0.51339035, 0.71492226, 0.72921274, 3.5186147 , 0.63688034]),
'mean_score_time': array([0.56574373, 0.62954168, 0.61716914, 0.54857082, 0.60307431,
0.56305232, 0.23738523, 0.59835744, 0.65009041, 0.24927506]),
'std_score_time': array([0.01723779, 0.07616324, 0.04688067, 0.06467144, 0.08608341,
0.06335029, 0.04464928, 0.05438892, 0.13699055, 0.05129816]),
'param_min_samples_split': masked_array(data=[3, 2, 2, 10, 7, 10, 10, 5, 5, 7],
mask=[False, False, False, False, False, False, False, False,
False, False],
fill_value='?',
dtype=object),
'param_max_depth': masked_array(data=[30, 30, 50, 30, 30, None, 10, 50, None, 10],
mask=[False, False, False, False, False, False, False, False,
False, False],
fill_value='?',
dtype=object),
'params': [{'min_samples_split': 3, 'max_depth': 30},
{'min_samples_split': 2, 'max_depth': 30},
{'min_samples_split': 2, 'max_depth': 50},
{'min_samples_split': 10, 'max_depth': 30},
{'min_samples_split': 7, 'max_depth': 30},
{'min_samples_split': 10, 'max_depth': None},
{'min_samples_split': 10, 'max_depth': 10},
{'min_samples_split': 5, 'max_depth': 50},
{'min_samples_split': 5, 'max_depth': None},
{'min_samples_split': 7, 'max_depth': 10}],
'split0_test_score': array([0.85874143, 0.85928288, 0.85741788, 0.85236434, 0.85453014,
0.85296595, 0.80086632, 0.8564553 , 0.85657562, 0.79906148]),
'split1_test_score': array([0.85988449, 0.86090723, 0.86012514, 0.85356756, 0.85591385,
0.85555288, 0.79653471, 0.85976417, 0.8601853 , 0.79755745]),
'split2_test_score': array([0.86030562, 0.85771869, 0.85988449, 0.85368788, 0.85591385,
0.85332692, 0.79942245, 0.85681627, 0.85699675, 0.79286488]),
'split3_test_score': array([0.85302611, 0.85368788, 0.85266514, 0.84929611, 0.85007821,
0.84971724, 0.79075923, 0.85332692, 0.85308627, 0.79412826]),
'split4_test_score': array([0.86017688, 0.85933458, 0.85999639, 0.85361892, 0.85632633,
0.85488238, 0.80446423, 0.85849227, 0.85891342, 0.80530654]),
'mean_test_score': array([0.85842691, 0.85818625, 0.85801781, 0.85250696, 0.85455248,
0.85328907, 0.79840939, 0.85697098, 0.85715147, 0.79778372]),
'std_test_score': array([0.00275623, 0.00246491, 0.00285836, 0.00167844, 0.00231831,
0.00202619, 0.0045992 , 0.00217648, 0.00241619, 0.00437799]),
'rank_test_score': array([ 1, 2, 3, 8, 6, 7, 9, 5, 4, 10], dtype=int32)}rand_df.best_params_
// {'min_samples_split': 3, 'max_depth': 30}4. 피처 중요도(Feature Importances)
결정 나무에서 노드를 분기할 때 해당 피처가 클래스를 나누는데 얼마나 영향을 미쳤는지 표기하는 척도입니다. 0에 가까우면 클래스를 구분하는데 해당 피처의 영향이 거의 없다는 것이며, 1에 가까우면 해당 피처가 클래스를 나누는데 영향을 많이 줬다는 의미입니다.
rf9 = RandomForestClassifier(max_depth = 30, min_samples_split = 3, random_state = 2023)
rf9.fit(X_train, y_train)
proba9 = rf9.predict_proba(X_test)
roc_auc_score(y_test, proba9[:,1])
// 0.9272801391858032
proba9 = rf9.predict_proba(X_test)
proba9
array([[0.97666667, 0.02333333],
[0.87434777, 0.12565223],
[0.94416667, 0.05583333],
...,
[0.38888483, 0.61111517],
[0.96888889, 0.03111111],
[0.25548436, 0.74451564]])rf9.feature_importances_
array([1.19597451e-01, 2.12169097e-02, 4.55426307e-02, 5.63770318e-02,
2.05726199e-02, 3.08173980e-02, 9.74067304e-03, 5.13141792e-03,
8.83072295e-04, 2.21041310e-03, 3.05376018e-02, 3.29227544e-03,
2.11176776e-02, 2.92937307e-03, 9.13089633e-02, 2.21722326e-02,
5.57994029e-02, 1.29838711e-02, 3.42503570e-02, 2.73943421e-02,
2.95963655e-02, 7.18714231e-03, 7.42131772e-03, 3.45395542e-03,
3.95743516e-03, 1.96145061e-03, 2.67790340e-03, 1.91960671e-03,
3.90714233e-03, 3.45845064e-03, 2.99613484e-03, 3.55977787e-03,
2.45146619e-03, 3.00503065e-03, 2.90079303e-03, 2.74405324e-03,
8.20976969e-03, 2.53655584e-04, 1.25147108e-02, 1.53508309e-07,
5.91625275e-03, 8.10463966e-04, 6.63826385e-04, 3.82096452e-03,
2.21152172e-03, 1.20292432e-03, 1.12562804e-03, 3.90090229e-04,
1.87251668e-05, 1.19564794e-02, 1.35465031e-03, 1.05907303e-03,
5.41937214e-03, 2.39169269e-03, 1.54667042e-03, 1.12283937e-03,
4.50264941e-04, 9.67760759e-05, 1.05844446e-04, 0.00000000e+00,
8.86886831e-02, 1.02807279e-01, 4.66372935e-04, 2.90869071e-03,
4.17574915e-04, 1.72845616e-02, 1.21627561e-02, 3.49951574e-03,
3.84454422e-03, 4.56373587e-03, 3.64019600e-03])feat_imp = pd.DataFrame({
'features' : X_train.columns,
'importances' : rf9.feature_importances_
})
feat_imp
top10 = feat_imp.sort_values('importances', ascending=False).head(10)
top10
plt.figure(figsize = (5, 10))
sns.barplot(x='importances', y ='features', data=top10)



