
1. AirQualityUCI 데이터셋
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltair_df = pd.read_csv('/content/drive/MyDrive/KDT/머신러닝과 딥러닝/data/AirQualityUCI.csv')
air_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9471 entries, 0 to 9470
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 9357 non-null object
1 Time 9357 non-null object
2 CO(GT) 9357 non-null float64
3 PT08.S1(CO) 9357 non-null float64
4 NMHC(GT) 9357 non-null float64
5 C6H6(GT) 9357 non-null float64
6 PT08.S2(NMHC) 9357 non-null float64
7 NOx(GT) 9357 non-null float64
8 PT08.S3(NOx) 9357 non-null float64
9 NO2(GT) 9357 non-null float64
10 PT08.S4(NO2) 9357 non-null float64
11 PT08.S5(O3) 9357 non-null float64
12 T 9357 non-null float64
13 RH 9357 non-null float64
14 AH 9357 non-null float64
15 Unnamed: 15 0 non-null float64
16 Unnamed: 16 0 non-null float64
dtypes: float64(15), object(2)
memory usage: 1.2+ MB- Date: 측정 날짜
- Time: 측정 시간
- CO(GT): 일산화탄소 농도 (mg/m^3)
- PT08.S1(CO): 일산화탄소에 대한 센서 응답
- NMHC(GT): 비메탄 탄화수소 농도 (microg/m^3)
- C6H6(GT): 벤젠 농도 (microg/m^3)
- PT08.S2(NMHC): 탄화수소에 대한 센서 응답
- NOx(GT): 산화 질소 농도 (ppb)
- PT08.S3(NOx): 산화 질소에 대한 센서 응답
- NO2(GT): 이산화질소 농도 (microg/m^3)
- PT08.S4(NO2): 이산화질소에 대한 센서 응답
- PT08.S5(O3): 오존에 대한 센서 응답
- T: 온도 (°C)
- RH: 상대 습도 (%)
- AH: 절대 습도 (g/m^3)
# 필요 없는 열 삭제
air_df.drop(['Unnamed: 15', 'Unnamed: 16'], axis = 1, inplace=True)
# 데이터에 na가 포함되어 있다면 제거
air_df= air_df.dropna()# Date 컬럼의 데이터를 datetime형식으로 변환
# 날짜-월-년도 형식으로 유지
air_df['Date'] = pd.to_datetime(air_df.Date,format='%d-%m-%Y')
air_df.head()
# Month 파생변수 만들기
# Date 컬럼에서 월을 추출
air_df['month'] = air_df['Date'].dt.month
air_df.head()
# hour 파생변수 만들기
# time에서 시간만 추출
air_df['Time'] = pd.to_datetime(air_df['Time'], format='%H:%M:%S')
air_df['Hour'] = air_df['Time'].dt.hour.astype(int)
# air_df['Hour] = air_df['Time'].str.split(':').str[0].fillna(0).astype(int)
air_df.head()
# Date,Time 컬럼을 제거
air_df.drop(['Date','Time'], axis=1, inplace=True)
air_df.head()
# heatmap을 통해 상관관계를 확인
plt.figure(figsize=(12,12))
sns.heatmap(air_df.corr(), cmap = 'coolwarm', vmax=1, vmin= -1, annot= True)
plt.show()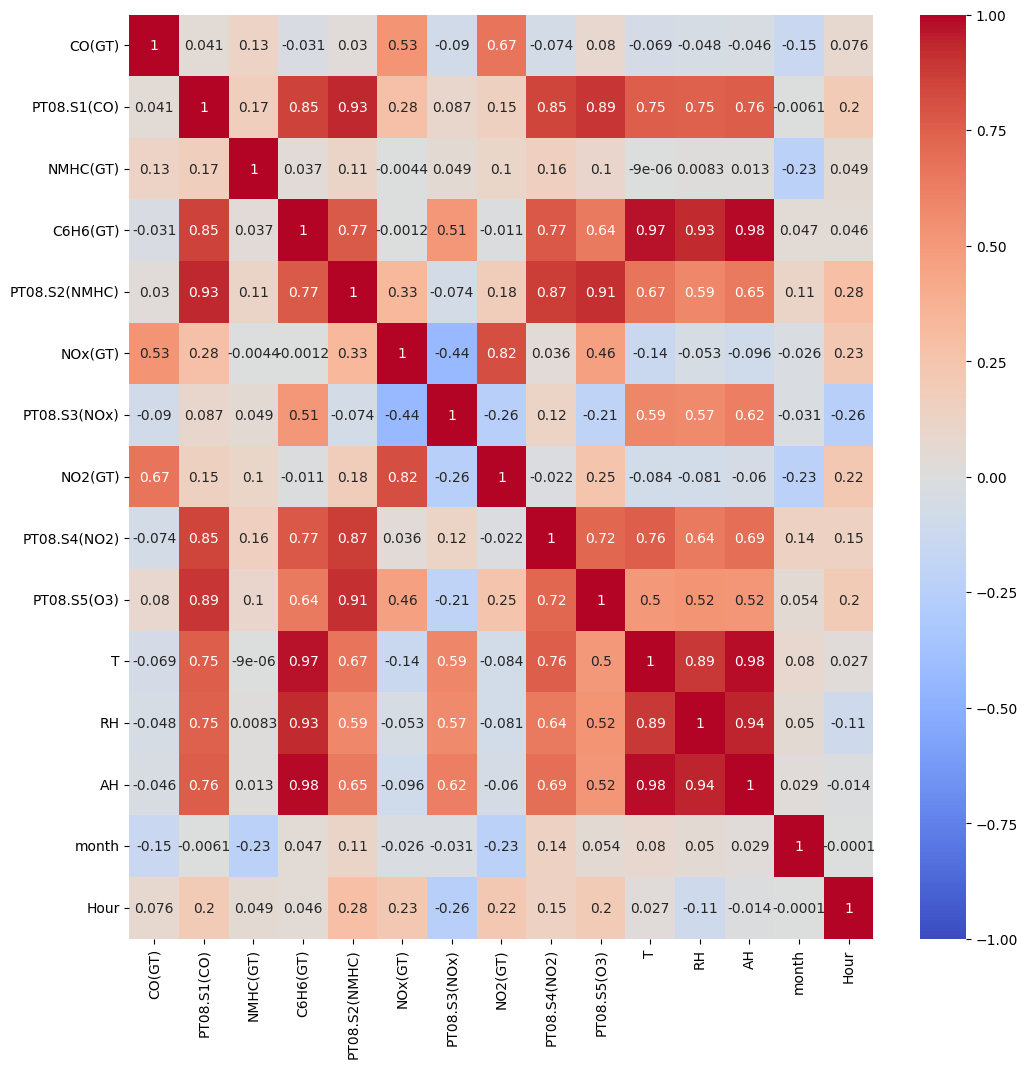
- StandardScaler로 정규화
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
ss = StandardScaler()
X = air_df.drop('RH', axis=1)
y = air_df['RH']
Xss = ss.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(Xss, y, test_size = 0.2, random_state=2023)
X_train.shape, y_train.shape // ((7485, 14), (7485,))
X_test.shape, y_test.shape // ((1872, 14), (1872,))2. 모델별 성능 확인을 위한 함수
my_predictions = {}
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato']
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True)
plt.figure(figsize=(12, 9))
plt.scatter(df.index, df['prediction'], marker='x', color='r')
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black')
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()
# 예측, 실제값
def mse_eval(name_, pred, actual):
global my_predictions
global colors
plot_predictions(name_, pred, actual)
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df)
plt.figure(figsize=(10, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['mse'])
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('MSE Error', fontsize=18)
plt.xlim(min_, max_)
plt.show()[ 성능 비교 ]
# Linear Regression
# Decision Tree Regression
# Random Forest Regression
# Suppert Bector Machine
# lightGBM
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from lightgbm import LGBMRegressor
lr = LinearRegression()
dtr = DecisionTreeRegressor(random_state=2023)
rf = RandomForestRegressor()
svm = SVR()
base_model = LGBMRegressor(random_state=2023)
lr.fit(X_train, y_train)
dtr.fit(X_train, y_train)
rf.fit(X_train, y_train)
svm.fit(X_train,y_train)
base_model.fit(X_train,y_train)pred1 = lr.predict(X_test)
pred2 = dtr.predict(X_test)
pred3 = rf.predict(X_test)
pred4 = svm.predict(X_test)
pred5 = base_model.predict(X_test)
rs1 = np.sqrt(mean_squared_error(y_test, pred1))
rs2 = np.sqrt(mean_squared_error(y_test, pred2))
rs3 = np.sqrt(mean_squared_error(y_test, pred3))
rs4 = np.sqrt(mean_squared_error(y_test, pred4))
rs5 = np.sqrt(mean_squared_error(y_test, pred5))
print(rs1,rs2,rs3,rs4,rs5)
// 7.3316009912232705 1.1906531461890633 0.5864489734872707 19.462400854771953 0.7736864001011999mse_eval('LinearRegression', pred1, y_test)
mse_eval('DecisionTreeRegressor', pred2, y_test)
mse_eval('RandomForestRegressor', pred3, y_test)
mse_eval('SVR', pred4, y_test)
mse_eval('LGBMRegressor', pred5, y_test)





dict = {'LinearRegression' : rs1, 'DecisionTreeRegressor': rs2, 'RandomForestRegressor':rs3, 'SVR':rs4,'LGBMRegressor':rs5 }res = [key for key in dict if all(dict[temp] >= dict[key] for temp in dict)]
print(res) // ['RandomForestRegressor']
min = {k: dict[k] for k in dict.keys() & set(res)}
print(min) // {'RandomForestRegressor': 0.5864489734872707}X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2023)
models = {
"Linear Regression": LinearRegression(),
"Decision Tree": DecisionTreeRegressor(),
"Random Forest": RandomForestRegressor(),
"Gradient Boosting": GradientBoostingRegressor()
}
# Train and evaluate the models
results = {}
for name, model in models.items():
model.fit(X_train, y_train)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
results[name] = mse
results



