1. 손글씨 데이터셋
from sklearn.datasets import load_digitsdigits = load_digits()digits.keys()
// dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])data = digits['data']
data.shape // (1797, 64)
target = digits['target']
target.shape // (1797,)
target // array([0, 1, 2, ..., 8, 9, 8])data의 64개의 8*8 픽셀위치의 정보가 합해져서 숫자 손글씨가 완성됩니다.
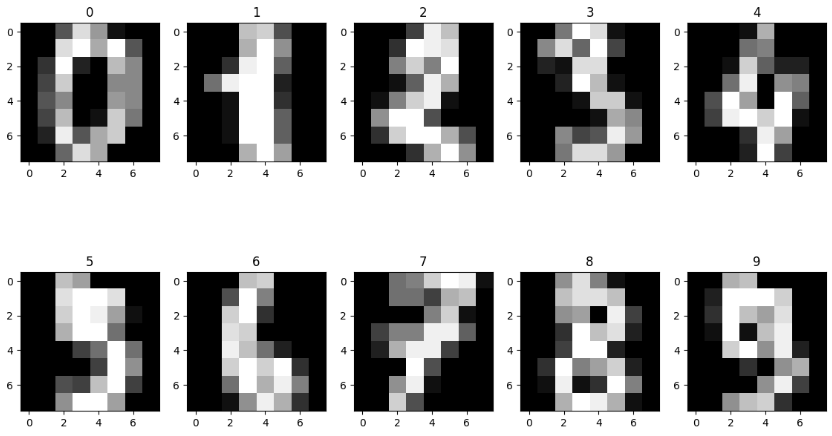
import matplotlib.pyplot as plt# 2행 5열의 서브플롯 그리드를 생성
fig, axes = plt.subplots(2, 5, figsize = (14,8))
# axes는 각 서브플롯을 나타내는2차원 배열
for i, ax in enumerate(axes.flatten()):
ax.imshow(data[i].reshape((8,8)),cmap ='gray')
ax.set_title(target[i])2*5의 다차원 배열을 flatten을 사용하여 1차원으로 펼쳐 하나의 반복 가능한 객체로 만들어주고
imshow()함수를 통해 데이터를 시각화 합니다. data[i].reshape((8,8)): data 리스트에서 i번째 데이터를 가져와 8x8 크기로 재구성합니다. 이는 64개의 픽셀로 이루어진 이미지를 나타냅니다.
# target.shape[0] // 5 = 359줄
fig, axes = plt.subplots(target.shape[0]//5, 5, figsize = (14,8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(data[i].reshape((8,8)),cmap ='gray')
ax.set_title(target[i])
데이터가 너무 많아 숫자가 선명히 보이지는 않지만, 359행, 5열로 이미지가 표출됩니다.
2. 스케일링(Scaling)
데이터 스케일링은 다양한 머신러닝 알고리즘에서 중요한 전처리 단계 중 하나로, 데이터를 일정한 범위나 특정한 스케일(크기)로 조정하는 과정입니다. 이는 다차원의 값들을 비교 분석하기 쉽게 만들어주며, 모델 학습 시 안정성과 수렴 속도를 향상시킵니다. 또한, 데이터의 오버플로우나 언더플로우를 방지하여 최적화 과정에서의 안정성을 높입니다.
2-1. 스케일링의 종류
- StandardScaler
- 평균과 표준편차를 사용하여 스케일링합니다. 주로 정규분포를 따르는 데이터에 적합하며, 각 특성(feature)의 평균이 0이고 표준편차가 1이 되도록 조정합니다.
- MinMaxScaler
- 최대값과 최소값을 이용하여 스케일링합니다. 각 특성의 최대값이 1, 최소값이 0이 되도록 조정합니다. 데이터 분포가 정규분포와 크게 다를 때도 유용합니다.✔️ 작은 숫자일수록 계산이 빠르기 때문에 대용량 데이터나 실시간 학습에서 효과적으로 사용됩니다.
- RobustScaler
- 중앙값과 IQR(Interquartile Range; 중간 50% 범위)를 이용하여 스케일링합니다. 중앙값과 IQR를 사용하므로 아웃라이어(이상치)의 영향을 덜 받습니다.
import pandas as pd
# 네이버 평점은 10점 만점, 넷플릭스 평점은 5점 만점인 경우
movie = {'naver' : [2, 4, 6, 8, 10], 'netflix': [1, 2, 3, 4, 5]}
movie = pd.DataFrame(data = movie)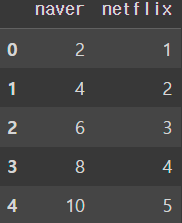
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScalermin_max_scaler = MinMaxScaler()
min_max_scaler = min_max_scaler.fit_transform(movie)
print(min_max_scaler)
array([[0. , 0. ],
[0.25, 0.25],
[0.5 , 0.5 ],
[0.75, 0.75],
[1. , 1. ]])
pd.DataFrame(min_max_scaler,columns=['naver', 'netflix'])
2-1. 정규화 (Normalization)
정규화는 데이터의 크기를 조절하여 서로 다른 특성 값의 범위를0~1 사이의 값으로 일치시키는 프로세스를 의미합니다. 정규화는 주로 데이터의 크기에 따른 영향을 줄이고, 특성 간의 상대적인 중요성을 균등하게 만들기 위해 사용됩니다. scikit-learn에서는 데이터 정규화를 위해 가장 일반적으로 MinMaxScaler와 같은 스케일러를 사용합니다.
data[0]
array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13., 15., 10.,
15., 5., 0., 0., 3., 15., 2., 0., 11., 8., 0., 0., 4.,
12., 0., 0., 8., 8., 0., 0., 5., 8., 0., 0., 9., 8.,
0., 0., 4., 11., 0., 1., 12., 7., 0., 0., 2., 14., 5.,
10., 12., 0., 0., 0., 0., 6., 13., 10., 0., 0., 0.])
scaler = MinMaxScaler()
scaled = scaler.fit_transform(data)
scaled[0]
array([0. , 0. , 0.3125 , 0.8125 , 0.5625 ,
0.0625 , 0. , 0. , 0. , 0. ,
0.8125 , 0.9375 , 0.625 , 0.9375 , 0.3125 ,
0. , 0. , 0.1875 , 0.9375 , 0.125 ,
0. , 0.6875 , 0.5 , 0. , 0. ,
0.26666667, 0.75 , 0. , 0. , 0.5 ,
0.53333333, 0. , 0. , 0.35714286, 0.5 ,
0. , 0. , 0.5625 , 0.57142857, 0. ,
0. , 0.25 , 0.6875 , 0. , 0.0625 ,
0.75 , 0.4375 , 0. , 0. , 0.125 ,
0.875 , 0.3125 , 0.625 , 0.75 , 0. ,
0. , 0. , 0. , 0.375 , 0.8125 ,
0.625 , 0. , 0. , 0. ])from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled, target, test_size = 0.2, random_state=2023)
print(X_train.shape, y_train.shape) // (1437, 64) (1437,)
print(X_test.shape, y_test.shape) // (360, 64) (360,)
2-3. 표준화(Standardization)
표준화는 데이터의 각 특성(feature)을 평균이 0이고 표준편차가 1이 되도록 변환하는 과정을 말합니다. 표준화는 주로 정규분포를 따르는 데이터를 다룰 때 사용되며, 이 역시 scale이 큰 feature의 영향이 비대해지는 것을 방지하고 각 특성의 중요도를 동일하게 만들어주고, 이상치의 영향을 줄일 수 있습니다. scikit-learn에서는 주로 StandardScaler를 사용하여 표준화합니다.
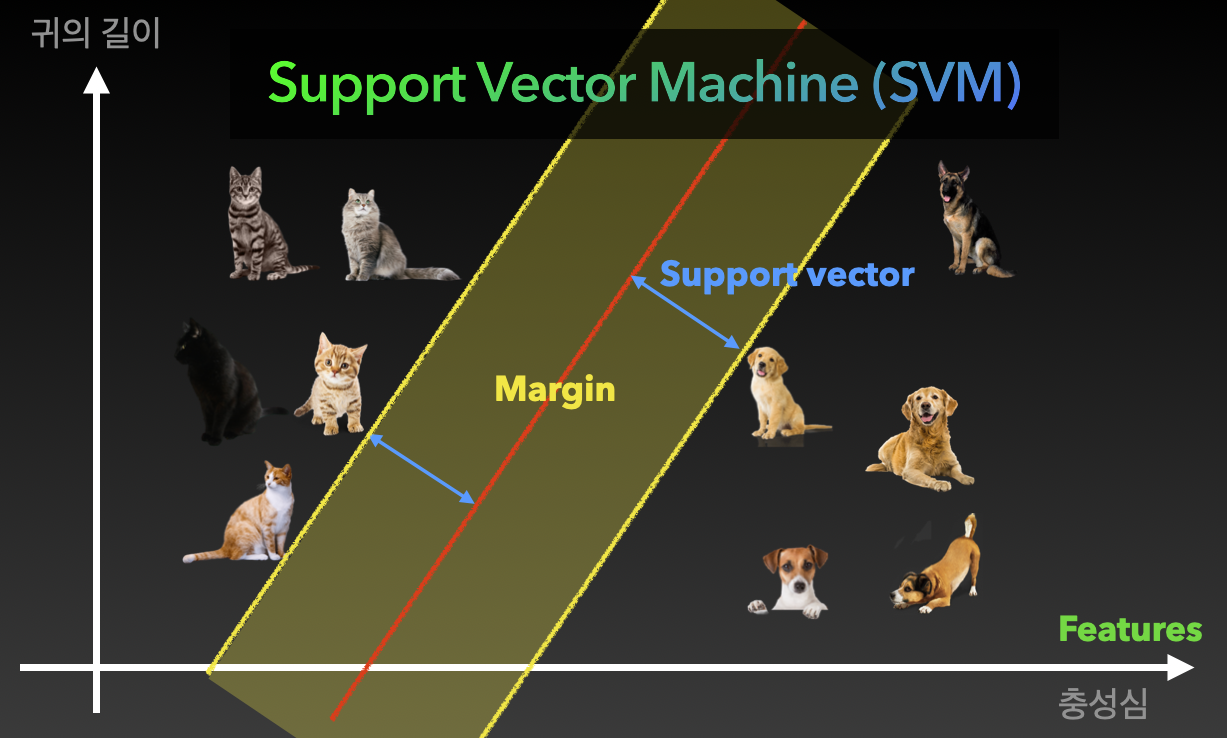
3. 서포트 벡터 머신(Support Vector Machine, SVM)
서포트 백터 머신은 데이터의 특성 공간에서 최대 폭을 가진 결정 경계(하이퍼플레인)를 찾아내는 알고리즘입니다. 주로 분류 문제에 활용되지만, 변형을 통해 회귀 문제에도 적용할 수 있습니다. SVM의 핵심 아이디어는 클래스 간의 경계를 정의하며, 이 경계는 데이터를 가장 잘 나누는 초평면(하이퍼플레인)으로 표현됩니다. 이 초평면은 클래스 간의 거리, 즉 마진을 최대화하는 것이 목표입니다. 모델의 일반화 능력을 향상시키기 위해 SVM은 결정 경계에 가장 가까이 있는 일부 데이터 포인트를 서포트 벡터라고 합니다. 이 서포트 벡터들은 결정 경계의 위치를 결정하는 데 중요한 역할을 합니다. 마진은 결정 경계와 서포트 벡터 사이의 거리로, SVM은 이를 최대화하는 방향으로 작동하여 모델의 성능을 향상시킵니다. SVM은 선형 분리가 불가능한 경우 커널 함수를 이용해 비선형 결정 경계를 찾을 수 있습니다. 따라서 SVM은 데이터 간의 복잡한 관계를 고려하여 최적의 결정 경계를 찾아내는 강력한 머신러닝 알고리즘 중 하나입니다.
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
model = SVC()
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
accuracy_score(y_test, y_pred)
// 0.991666666666666799% 정답률
print(y_test[10], y_pred[10])
// 3 3
plt.imshow(X_test[10].reshape(8,8))
plt.show()
fig, axes = plt.subplots(2, 5, figsize = (14,8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(X_test[i].reshape((8,8)),cmap ='gray')
ax.set_title(f'Label: {y_test[i]}, pred: {y_pred[i]}')test 데이터를 이미지로 출력해보고, title에 test데이터와 예측결과를 프린트 해봄

'AI' 카테고리의 다른 글
| 앙상블 모델 (0) | 2023.12.29 |
|---|---|
| 랜덤 포레스트(데이터 전처리) (0) | 2023.12.28 |
| 로지스틱 회귀 (0) | 2023.12.27 |
| 의사 결정 나무(자전거 대여 예제) (0) | 2023.12.26 |
| 선형 회귀(랜트비 예측) (1) | 2023.12.26 |



