1. 에일리언 vs 프레데터 데이터셋
https://www.kaggle.com/datasets/pmigdal/alien-vs-predator-images
Alien vs. Predator images
Small image classification - for transfer learning
www.kaggle.com
- 케글 로그인 -> 우측 상단 계정 클릭 -> Your Profile -> 중앙에 Account를 클릭 -> API 항목에 Create New API Token -> kaggle.json이 다운로드 됨
- copy API command 해서 ! 뒤에 붙여넣기
- 압출 풀기 : !unzip -q 파일이름
import os
os.environ['KAGGLE_USERNAME'] = "아이디"
os.environ['KAGGLE_KEY'] = "배포받은 키값"!kaggle datasets download -d pmigdal/alien-vs-predator-images
!unzip -q alien-vs-predator-images.zipimport torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoaderdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device) // cpu2. 이미지 증강 기법(Image Augmentation)
이미지 증강(Image Augmentation)은 컴퓨터 비전 및 딥러닝 분야에서 널리 사용되는 기술 중 하나로, 학습 데이터의 다양성을 높이기 위해 이미지에 다양한 변환을 적용하는 과정을 말합니다. 이 기법은 모델의 일반화 성능을 향상시키고, overfitting을 방지하며, 다양한 환경에서의 강인성을 강화하는 데 도움이 됩니다. 아래는 주로 사용되는 이미지 증강 기법 몇 가지입니다:
- 회전 (Rotation): 이미지를 특정 각도로 회전시켜 새로운 관점에서 데이터를 확장합니다.
- 이동 (Translation): 이미지를 수평 및 수직으로 이동시켜 다양한 위치에서의 객체를 모델이 학습할 수 있도록 합니다.
- 확대/축소 (Scaling): 이미지의 크기를 조절하여 다양한 크기의 객체를 인식할 수 있게 합니다.
- 반전 (Flip): 이미지를 수평 또는 수직으로 뒤집어서 다른 방향에서의 물체를 학습할 수 있게 합니다.
- 클리핑 (Crop): 이미지의 일부를 잘라내어 크롭하거나, 큰 이미지에서 작은 부분을 추출하여 학습 데이터를 다양하게 만듭니다.
- 밝기 조절 (Brightness Adjustment): 이미지의 밝기를 조절하여 다양한 조명 상태에서의 학습을 가능하게 합니다.
- 콘트라스트 조절 (Contrast Adjustment): 이미지의 콘트라스트를 변경하여 다양한 환경에서 모델을 강화합니다.
- 노이즈 추가 (Noise Injection): 이미지에 노이즈를 추가하여 모델이 노이즈에 강인하게 대응할 수 있게 합니다.
https://pytorch.org/vision/master/transforms.html
Transforming and augmenting images — Torchvision main documentation
Shortcuts
pytorch.org
data_transforms = {
'train' : transforms.Compose([ # Compose : 한꺼번에 묶어서 실행
transforms.Resize((224,224)),
# (각도(처음 넣는 데이터라서 이름 생략), 찌그러뜨림, 크기(범위))
transforms.RandomAffine(0, shear = 10, scale=(0.8, 1.2)),
# 수평으로 뒤집기
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
'validation' : transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()])
}
def target_transforms(target):
return torch.FloatTensor([target])image_datasets = {
# 키값 이름으로 데이터셋 객체가 만들어짐
'train': datasets.ImageFolder('data/train', data_transforms['train'], target_transform=target_transforms),
'validation': datasets.ImageFolder('data/validation', data_transforms['validation'], target_transform=target_transforms)
}dataloaders = {
'train' : DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation': DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}print(len(image_datasets['train']), len(image_datasets['validation']))
// 694 200imgs, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(4, 8, figsize=(16,8))
for ax, img, label in zip(axes.flatten(), imgs, labels):
# 찍으려먼 가로,세로,컬러 순서여야 함. 근데 데이터는 컬러,가로,세로 순서여서 permute로 순서 바꿔줌
ax.imshow(img.permute(1,2,0))
ax.set_title(label.item())
ax.axis('off')
3. 전이학습 (Transfer Learning)
전이 학습(Transfer Learning)은 하나의 작업을 위해 훈련된 모델을 유사한 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법 중 하나입니다. 신경망을 처음부터 새로 학습하는 것보다 전이 학습을 통해 모델을 업데이트하고 재학습하는 것이 더 빠르고 효율적이라는 장점이 있습니다. 이는 다양한 응용 분야(이미지 분류, 객체 감지, 음성 인식, 검색 분야 등)에서 널리 사용되고 있습니다.
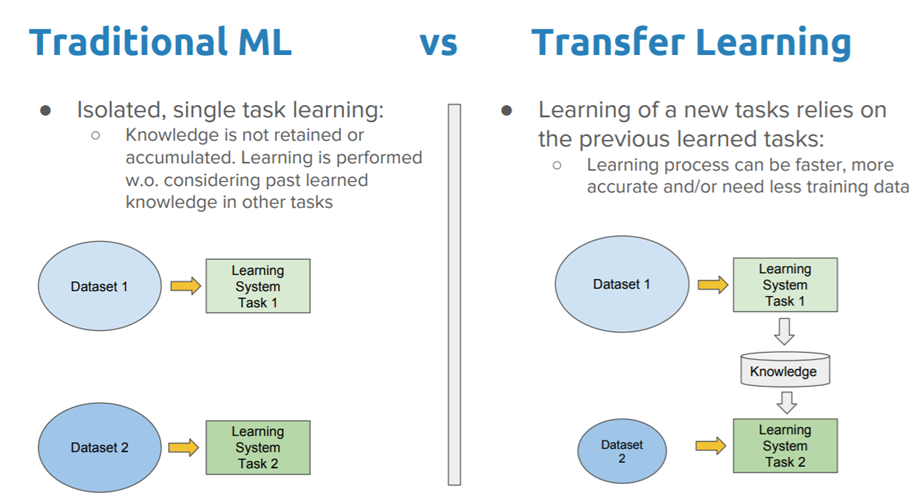
3-1. 전이 학습의 고려할 점
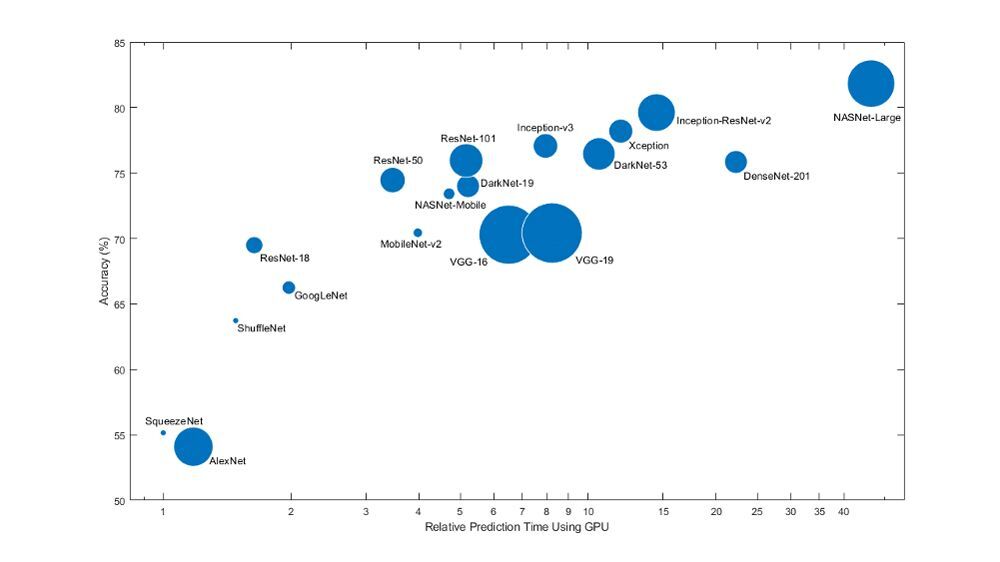
- 크기 : 모델의 크기는 배포할 위치와 방법에 따라 달라집니다.
- 속도 및 정확도: 하드웨어, 배치 크기와 같은 요소를 고려해야합니다.
4. 사전 학습된 ResNet50 모델 사용하기
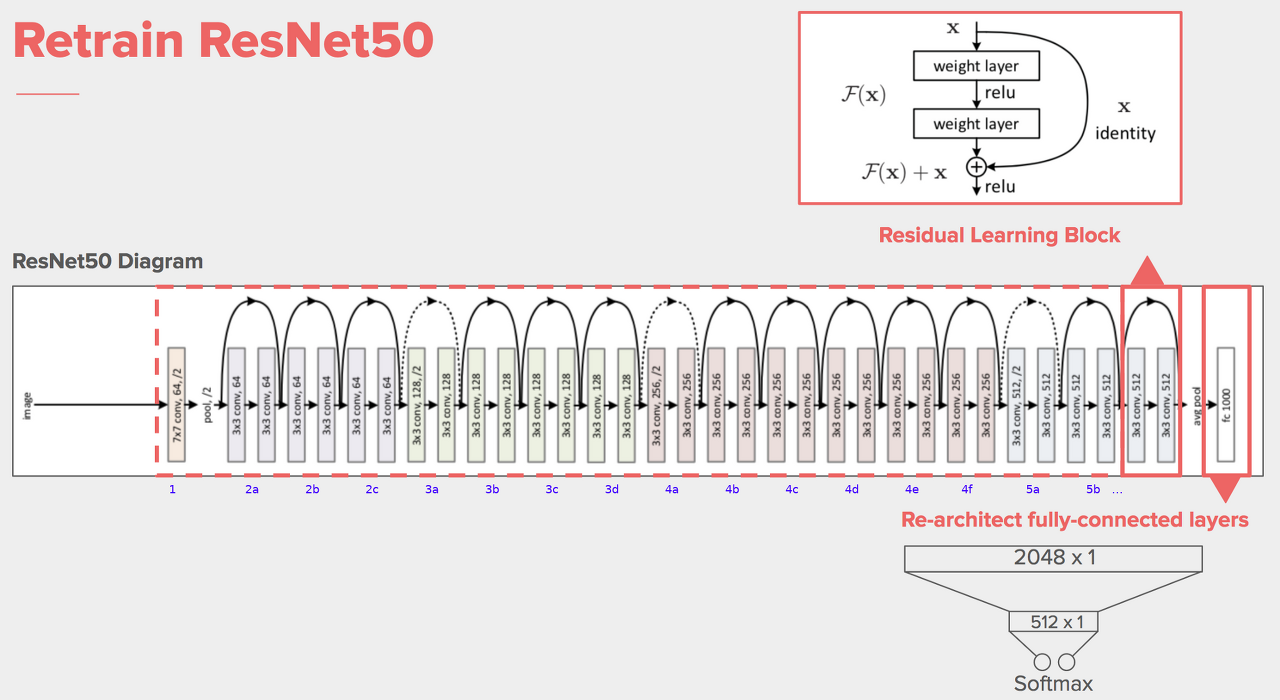
ResNet50은 딥러닝에서 널리 사용되는 합성곱 신경망(Convolutional Neural Network, CNN) 중 하나로, 마이크로소프트(Microsoft)에서 개발한 ResNet(Residual Network) 시리즈 중의 하나입니다. ResNet은 깊은 신경망을 효과적으로 훈련시킬 수 있게 해주는 잔차 학습(Residual Learning)의 아이디어를 도입하여, 이전의 더 얕은 신경망보다도 더 깊은 신경망을 구축할 수 있게 했습니다.
ResNet50의 이름에서 "50"은 모델에 포함된 총 레이어 수를 나타냅니다. 이 모델은 50개의 레이어로 구성되어 있으며, 이 중 일부는 합성곱 레이어, 풀링 레이어, 배치 정규화 레이어 등으로 이루어져 있습니다.
- 잔차 블록(Residual Block): ResNet의 핵심 아이디어는 잔차 블록입니다. 기존의 딥러닝 모델들은 층이 깊어질수록 성능이 감소하는 문제가 있었는데, 잔차 블록은 스킵 연결(skip connection)을 도입하여 입력을 출력에 직접 더해주는 방식으로 학습을 진행합니다. 이렇게 함으로써 기울기 소실 문제를 해결하고 더 깊은 네트워크를 학습할 수 있게 합니다.
Models and pre-trained weights — Torchvision 0.16 documentation
Shortcuts
pytorch.org
5. 이미지넷(ImageNet)
ImageNet은 대표적인 대규모 데이터셋으로, 20,000개가 넘는 카테고리를 가지고 있으며, 각 카테고리별로 수백개의 이미지를 포함하고 있습니다. 이 데이터셋은 다양한 종류의 객체와 장면을 포함하고 있어서 컴퓨터 비전 분야에서 모델을 훈련하고 평가하는 데 널리 사용되고 있습니다. ImageNet Large Scale Visual Recognition Challenge(ILSVRC)와 연관되어 있으며, 많은 딥러닝 모델이 ImageNet 데이터셋을 활용하여 사전 훈련(pre-training)되었습니다.

model = models.resnet50(weights='IMAGENET1K_V1').to(device)
print(model)Downloading: "https://download.pytorch.org/models/resnet50-0676ba61.pth" to /root/.cache/torch/hub/checkpoints/resnet50-0676ba61.pth
100%|██████████| 97.8M/97.8M [00:01<00:00, 74.1MB/s]
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
.
.
.
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)6. Freeze Layers
- 특징을 뽑아내는 CNN의 앞쪽 컨볼루션 레이어들은 학습을 하지 않도록 설정
- 출력 부분의 레이어(fc)를 다시 설정하여 분류에 맞게 변경
# 가져온 파라미터 (W, b)를 업데이트하지 않음
for param in model.parameters():
param.requires_grad = False# 레이어를 필요한 분류 형태에 맞춰서 재설정
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
).to(device)
print(model)ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
.
.
.
(fc): Sequential(
(0): Linear(in_features=2048, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=1, bias=True)
(3): Sigmoid()
)
)
- 학습 & 결과 보기
# train, test 한번에 돌리기
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.BCELoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss
y_bool = (y_pred >= 0.5).float()
acc = (y_batch == y_bool).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}: Epoch {epoch+1:4d}/{epochs} Loss: {avg_loss:.4f} Accuracy: {avg_acc: .2f}%')
train : Epoch 1/10 Loss: 0.1861 Accuracy: 92.61%
validation: Epoch 1/10 Loss: 0.2674 Accuracy: 89.29%
train : Epoch 2/10 Loss: 0.1092 Accuracy: 96.31%
validation: Epoch 2/10 Loss: 0.1825 Accuracy: 91.96%
train : Epoch 3/10 Loss: 0.1736 Accuracy: 91.62%
validation: Epoch 3/10 Loss: 0.2006 Accuracy: 90.63%
train : Epoch 4/10 Loss: 0.1367 Accuracy: 94.19%
validation: Epoch 4/10 Loss: 0.2456 Accuracy: 89.29%
train : Epoch 5/10 Loss: 0.1418 Accuracy: 95.04%
validation: Epoch 5/10 Loss: 0.2321 Accuracy: 90.63%
train : Epoch 6/10 Loss: 0.1315 Accuracy: 94.74%
validation: Epoch 6/10 Loss: 0.2035 Accuracy: 91.07%
train : Epoch 7/10 Loss: 0.1833 Accuracy: 92.41%
validation: Epoch 7/10 Loss: 0.3319 Accuracy: 83.93%
train : Epoch 8/10 Loss: 0.1427 Accuracy: 93.90%
validation: Epoch 8/10 Loss: 0.1949 Accuracy: 93.30%
train : Epoch 9/10 Loss: 0.1599 Accuracy: 93.69%
validation: Epoch 9/10 Loss: 0.2035 Accuracy: 90.18%
train : Epoch 10/10 Loss: 0.0881 Accuracy: 97.38%
validation: Epoch 10/10 Loss: 0.1924 Accuracy: 91.07%
from PIL import Image
img1 = Image.open('/content/data/validation/alien/19.jpg')
img2 = Image.open('/content/data/validation/predator/20.jpg')
fig, axes = plt.subplots(1,2,figsize=(12,6))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()
img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
print(img1_input.shape) // torch.Size([3, 224, 224])
print(img2_input.shape) // torch.Size([3, 224, 224])
# 흑백 한장, 컬러 한장을 같이 넣으려면 [2, 3, 224, 224] 가 되어야함
# .stack : 텐서의 목록을 하나의 텐서로 쌓아올리는 함수
test_batch = torch.stack([img1_input, img2_input])
test_batch = test_batch.to(device)
test_batch.shape // torch.Size([2, 3, 224, 224])# 두 장의 사진을 test하기 위해 stack함수를 사용해서 test_batch에 함께 넣어준다.
y_pred = model(test_batch)
y_pred // tensor([[0.0151],
[0.8611]], device='cuda:0', grad_fn=<SigmoidBackward0>)
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].set_title(f'{(1-y_pred[0, 0])*100:.2f}% Alien, {(y_pred[0, 0])*100:.2f}% Predator')
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title(f'{(1-y_pred[1, 0])*100:.2f}% Alien, {(y_pred[1, 0])*100:.2f}% Predator')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()
'AI' 카테고리의 다른 글
| 자연어 처리 개요 (0) | 2024.01.16 |
|---|---|
| 포켓몬 분류 해보기 (1) | 2024.01.14 |
| 간단한 CNN모델 만들기 실습 (1) | 2024.01.11 |
| CNN 기초 (0) | 2024.01.10 |
| 비선형 활성화 함수 (0) | 2024.01.10 |



