
1. 판다스
판다스(Pandas)는 파이썬 프로그래밍 언어를 위한 데이터 조작과 분석을 위한 라이브러리입니다. 주로 표 형식의 데이터나 다양한 형태의 데이터를 다루는 데 사용됩니다. 표의 데이터 부분을 valuses, 행 이름을 index, 열 이름을 columns라고 부릅니다. 판다스는 크게 두 가지 자료 구조를 제공합니다.
⭐시리즈(Series): (index + values)
- 1차원 배열과 유사한 구조를 가진 데이터 구조입니다.
- 각 데이터에는 인덱스(index)가 부여되어 있습니다.
⭐ 데이터프레임(DataFrame): (index + columns + index)
- 2차원 테이블 형태의 데이터 구조입니다.
- 여러 개의 시리즈를 모아서 하나의 데이터프레임을 만들 수 있습니다.
설치 : !pip install pandas
data1 = [[67, 93, 91],
[75, 69, 96],
[75, 81, 82],
[62, 70, 75],
[98, 45, 87]]
idx1 = ['김사과', '반하나','오렌지','이메론','배애리']
col1 = ['국어', '영어', '수학']pd.DataFrame(data1)
pd.DataFrame(data1, idx1)
pd.DataFrame(data1, idx1, col1)
# 순서 상관없이 입력 방법
pd.DataFrame(index = idx1, columns=col1, data = data1)
위에서부터 순차적으로 인덱스와 컬럼을 더해본 모습입니다.
지정 없이 순차적으로 입력하면 values, index, columns가 됩니다.
df1 = pd.DataFrame(data1, idx1, col1)
print(df1.values)
array([[67, 93, 91],
[75, 69, 96],
[75, 81, 82],
[62, 70, 75],
[98, 45, 87]])
print(df1.index)
Index(['김사과', '반하나', '오렌지', '이메론', '배애리'], dtype='object')
print(df1.columns)
Index(['국어', '영어', '수학'], dtype='object')# Series
data2 = [67, 75, 75, 62, 98]
pd.Series(data2)
0 67
1 75
2 75
3 62
4 98
dtype: int64
pd.Series(data2, idx1)
김사과 67
반하나 75
오렌지 75
이메론 62
배애리 98
dtype: int64- 딕셔너리를 사용하여 데이터 프레임을 생성
dic1 = {
'국어': [67, 75, 75, 62, 98],
'영어': [93, 69, 81, 70, 45],
'수학': [91, 96, 82, 75, 87]
}
df2 = pd.DataFrame(data=dic1, index = idx1)
print(df2)
국어 영어 수학
김사과 67 93 91
반하나 75 69 96
오렌지 75 81 82
이메론 62 70 75
배애리 98 45 872. 엑셀파일 읽어오기
pd.read_excel('파일경로')3. CSV 파일 읽어오기
CSV는 Comma-Separated Values의 약자로, 텍스트 기반의 데이터 저장 형식 중 하나입니다. CSV 파일은 데이터를 행과 열의 형태로 저장하며, 각 값들은 쉼표(,)로 구분됩니다. CSV 파일은 데이터를 쉽게 읽고 쓸 수 있는 가벼운 텍스트 형식이기 때문에, 데이터 과학 및 프로그래밍에서 많이 사용됩니다. 판다스와 같은 라이브러리를 사용하면 CSV 파일을 읽어와 데이터프레임으로 변환하거나, 반대로 데이터프레임을 CSV 파일로 저장하는 등의 작업이 용이합니다.
pd.read_csv('csv 파일 경로')4. 데이터프레임 기본정보 알아보기

- info(): 행(row), 열(column)의 기본적인 정보와 데이터 타입을 반환
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15 entries, 0 to 14
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 15 non-null object # object는 문자열을 의미
1 그룹 14 non-null object
2 소속사 15 non-null object
3 성별 15 non-null object
4 생년월일 15 non-null object
5 키 13 non-null float64
6 혈액형 15 non-null object
7 브랜드평판지수 15 non-null int64
dtypes: float64(1), int64(1), object(6)
memory usage: 1.1+ KB- 컬럼명 변경하기
print(df.columns)
Index(['이름', '그룹', '소속사', '성별', '생년월일', '키', '혈액형', '브랜드평판지수'], dtype='object')
new_column = ['name', 'group', 'company', 'gender', 'birthday', 'height', 'blood', 'brand']
df.columns = new_column
print(df.columns)
Index(['name', 'group', 'company', 'gender', 'birthday', 'height', 'blood', 'brand'],dtype='object')- describe() : 계산 가능한 컬럼의 통계정보를 반환
df.describe()
height brand
count 13.000000 1.500000e+01
mean 175.792308 5.655856e+06
std 5.820576 2.539068e+06
min 162.100000 2.925442e+06
25% 174.000000 3.712344e+06
50% 177.000000 4.668615e+06
75% 179.200000 7.862214e+06
max 183.000000 1.052326e+07
# std: 표준편차 , mean : 평균, 50% : 중앙값- 문자열 포함해서 통계정보 보기
df.describe(include = object)
# freq : 얼마나 중복되는지 갯수
name group company gender birthday blood
count 15 14 15 15 15 15
unique 15 8 9 2 15 4
top 지민 방탄소년단 빅히트 남자 1995-10-13 A
freq 1 5 5 12 1 7- shape : 형태
df.shape
(15, 8)- head() : 상위 5개(기본 갯수)의 row를 출력. 괄호 안에 숫자 입력시, 해당 갯수만큼 출력
- tail() : 하위 5개(기본 갯수)의 row를 출력. 괄호 안에 숫자 입력시, 해당 갯수만큼 출력
df.head()
name group company gender birthday height blood brand
0 지민 방탄소년단 빅히트 남자 1995-10-13 173.6 A 10523260
1 지드래곤 빅뱅 YG 남자 1988-08-18 177.0 A 9916947
2 강다니엘 NaN 커넥트 남자 1996-12-10 180.0 A 8273745
3 뷔 방탄소년단 빅히트 남자 1995-12-30 178.0 AB 8073501
4 화사 마마무 RBW 여자 1995-07-23 162.1 A 7650928
df.tail()
name group company gender birthday height blood brand
10 태연 소녀시대 SM 여자 1989-03-09 NaN A 3918661
11 차은우 아스트로 판타지오 남자 1997-03-30 183.0 B 3506027
12 백호 뉴이스트 플레디스 남자 1995-07-21 175.0 AB 3301654
13 JR 뉴이스트 플레디스 남자 1995-06-08 176.0 O 3274137
14 슈가 방탄소년단 빅히트 남자 1993-03-09 174.0 O 2925442- 정렬하기
- sort_index() : index로 오름차순 정렬 / sort_index(ascending = False) : index로 내림차순 정렬
- df.sort_values(by='height') : by 값에 따라 오름차순 정렬
- df.sort_values(by='height', ascending = False ) : by 값에 따라 내림차순 정렬
df.sort_values(by='height')
- df.sort_values(by='height', na_position='first') # NaN값을 가장 위로 올림 (기본값은 last)
df.sort_values(by='height', na_position='first')
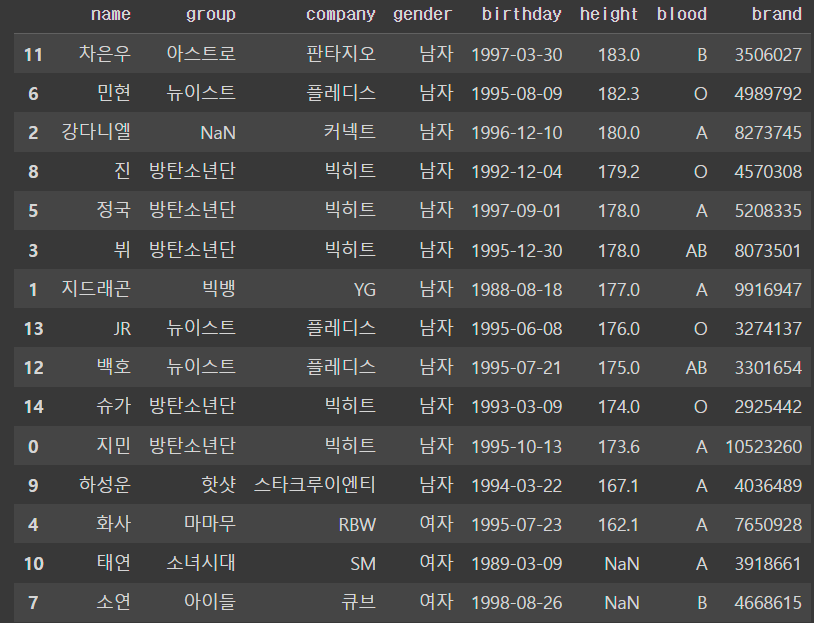
- 1차 정렬: 키(내림차순) + 2차 정렬: 브랜드(오름차순)
df.sort_values(by=['height', 'brand'], ascending=[False, True])
5. 데이터 다루기
- 특정 컬럼만 출력(series 출력)
df['blood'] = df.blood 동일한 결과
0 A
1 A
2 A
3 AB
4 A
5 A
6 O
7 B
8 O
9 A
10 A
11 B
12 AB
13 O
14 O
Name: blood, dtype: object
- 특정 인덱스만 출력
df[:3] # 인덱스 0~2까지
name group company gender birthday height blood brand
0 지민 방탄소년단 빅히트 남자 1995-10-13 173.6 A 10523260
1 지드래곤 빅뱅 YG 남자 1988-08-18 177.0 A 9916947
2 강다니엘 NaN 커넥트 남자 1996-12-10 180.0 A 8273745- lic 인덱싱: "레이블(이름) 인덱싱", 행과 열 모두 인덱싱과 슬라이싱이 가능
df.loc[:, 'name']
0 지민
1 지드래곤
2 강다니엘
3 뷔
4 화사
5 정국
6 민현
7 소연
8 진
9 하성운
10 태연
11 차은우
12 백호
13 JR
14 슈가
Name: name, dtype: objectdf.loc[2:5, 'name']
✔ 2번부터 5번 출력. 슬라이싱과 다르게 5번 포함!!
2 강다니엘
3 뷔
4 화사
5 정국
Name: name, dtype: object
df.loc[2:5, ['name', 'gender', 'height']]
name gender height
2 강다니엘 남자 180.0
3 뷔 남자 178.0
4 화사 여자 162.1
5 정국 남자 178.0
df.loc[2:5, "name":"gender"]
name group company gender
2 강다니엘 NaN 커넥트 남자
3 뷔 방탄소년단 빅히트 남자
4 화사 마마무 RBW 여자
5 정국 방탄소년단 빅히트 남자- iloc 인덱싱 : "index로 인덱싱". 행과 열 모두 인덱싱과 슬라이싱이 가능
df.iloc[:, 0] # 행은 모두, 열을 0번째 index만
0 지민
1 지드래곤
2 강다니엘
3 뷔
4 화사
5 정국
6 민현
7 소연
8 진
9 하성운
10 태연
11 차은우
12 백호
13 JR
14 슈가
Name: name, dtype: objectdf.iloc[1:5, 0:2] # 1~4번 행, 0~1번 열 출력
✔️ index로 하는 슬라이싱이기때문에
✔️ loc와는 다르게 슬라이싱처럼 ~직전까지 출력
name group
1 지드래곤 빅뱅
2 강다니엘 NaN
3 뷔 방탄소년단
4 화사 마마무- boolean indexing
df['height'] >= 180
0 False
1 False
2 True
3 False
4 False
5 False
6 True
7 False
8 False
9 False
10 False
11 True
12 False
13 False
14 False
Name: height, dtype: booldf[df['height'] >= 180]['name'] # True값인 곳만 출력됨
df['name'][df['height'] >= 180] # 두 식의 결과는 동일
2 강다니엘
6 민현
11 차은우
Name: name, dtype: objectdf[['name','gender','height']][df['height'] >= 180]
df.loc[df['height'] >= 180, ['name', 'gender', 'height']]
name gender height
2 강다니엘 남자 180.0
6 민현 남자 182.3
11 차은우 남자 183.0- isin(): 정의한 list에 있는 데이터를 색인
company = ['플레디스', 'SM']
df['company'].isin(company)
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 False
8 False
9 False
10 True
11 False
12 True
13 True
14 False
Name: company, dtype: booldf[df['company'].isin(company)]
name group company gender birthday height blood brand
6 민현 뉴이스트 플레디스 남자 1995-08-09 182.3 O 4989792
10 태연 소녀시대 SM 여자 1989-03-09 NaN A 3918661
12 백호 뉴이스트 플레디스 남자 1995-07-21 175.0 AB 3301654
13 JR 뉴이스트 플레디스 남자 1995-06-08 176.0 O 3274137df.loc[df['company'].isin(company)]
# df.loc[df['company'].isin(company), :] 동일
name group company gender birthday height blood brand
6 민현 뉴이스트 플레디스 남자 1995-08-09 182.3 O 4989792
10 태연 소녀시대 SM 여자 1989-03-09 NaN A 3918661
12 백호 뉴이스트 플레디스 남자 1995-07-21 175.0 AB 3301654
13 JR 뉴이스트 플레디스 남자 1995-06-08 176.0 O 3274137'데이터 분석' 카테고리의 다른 글
| 가상 쇼핑몰 데이터 예제 (0) | 2023.12.16 |
|---|---|
| Matplotlib (0) | 2023.12.10 |
| 판다스3 (0) | 2023.12.08 |
| 판다스2 (0) | 2023.12.08 |
| 넘파이 (0) | 2023.11.28 |


