
▶️ 머신러닝에서의 학습?
1. 지도 학습(supervised learning)
- 문제와 정답을 함께 학습하여 예측 또는 분류하는 방식입니다.
- 데이터의 정답에 영향을 미치는 특성들을 입력 변수/독립 변수(x)라고 하고, 레이블(정답)을 출력 변수/종속 변수(y)라고 합니다.
- 연속형 출력 변수의 경우에는 회귀 기술을 사용하고, 범주형 출력 변수의 경우에는 분류 기술을 사용합니다.
2. 비지도 학습(Unsupervised Learning)
- 출력 변수(y)가 없고, 입력 변수(x) 간의 관계를 모델링합니다.
- 클러스터링과 같은 군집 분석이나 association과 같이 데이터의 패턴이나 구조를 파악하는데 이용, PCA와 같이 차원을 줄이는 분석기법입니다.
3. 강화 학습(Reinforcement Learning)
- 지도 학습과 비지도 학습과는 다르게 시행착오를 통해 변화하는 환경으로 부터 학습합니다.
- 어떤 환경 안에서 최대의 보상을 가져다주는 행동이 무엇인지를 학습합니다.
- 최대의 보상을 얻을 수 있는 행동을 수행하는 것을 이용(exploitation)이라고 하고, 다양한 경험을 쌓기 위한 새로운 시도가 탐험(exploration)이라고 합니다. 이용과 탐험 사이의 적절한 균형을 갖추는 것이 핵심입니다.
지도 학습 - 분류(classification)
▶️ 의사 결정 나무(Decision Tree) ?
- 나무(tree)라는 표현을 쓰는 이유는 의사 결정 과정이 나무 줄기에서 가지가 뻗어나가는 모양과 유사하기 때문입니다.
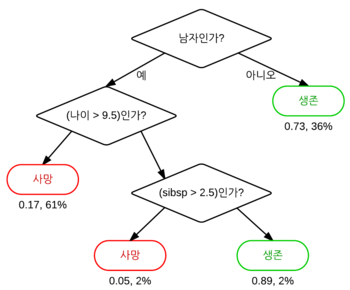
의사 결정 나무 구조에서 처음 시작하는 변수를 뿌리 노드라고 하고 중간 단계의 변수를 노드라고 하며 마지막 결과를 터미널 노드 또는 잎 노드라고 합니다. 위의 그림을 예시로 해보면 '남자/여자'를 구분하는 변수가 뿌리 노드가 되며, 마지막 사망과 생존 결과가 잎 노드가 됩니다.
의사 결정 나무에서 뿌리 노드는 전체 데이터를 가장 분명하게 구분할 수 있는 변수입니다. 다음 분기점에서는 남아있는 데이터를 가장 확실하게 구분 짓는 변수가 다음 노드가 됩니다.
엔트로피 계수?
한 집단의 불확실성 또는 불순도를 의미한다. 엔트로피가 높으면 집단의 성격이 균일하지 못하다고 표현한다.
따라서 모든 변수들의 엔트로피 값을 구한 후 엔트로피 값이 가장 작은 변수를 노드로 설정한다.
지니 불순도?
지니 불순도는 집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표이며 엔트로피 계수를 대체할 수 있다.
집합에 있는 항목이 모두 같다면 지니 불순도는 0을 갖게되며 완전히 순수하다고 표현한다.
- 분류 트리 분석은 예측된 결과로 입력 데이터가 분류되는 클래스를 출력한다.
- 회귀 트리 분석은 예측된 결과로 특정 의미를 지니는 실수 값을 출력한다. (예: 주택의 가격, 환자의 입원 기간)
| [ 장점 ] | [ 단점 ] |
| - 결과를 해석하고 이해하기 쉽다. - 자료를 가공할 필요가 거의 없다. - 회귀와 분류가 모두 가능하다. - 대규모 데이터 셋에서도 잘 동작한다. |
- 데이터의 특성이 특정 변수에 수직/수평적으로 구분되지 못할 때 분류율이 떨어진다. - 오버피팅이 잘 일어날 수 있다. |
▶️ 앙상블 (Ensemble Learning) ?
https://junyealim.tistory.com/90
앙상블 모델
앙상블은 여러 개별 모델을 결합하여 하나의 강력한 모델을 형성하는 기술입니다. 이는 각 모델의 약점을 서로 보완하고 강점을 결합하여 높은 정확도와 안정성을 달성하는 데 도움이 됩니다. 1
junyealim.tistory.com
[간단 정리]
- 보팅(Voting) : 한 데이터셋에 대해 서로 다른 알고리즘을 가진 분류기들을 결합. 다수결 혹은 평균으로 다양한 분류기의 예측을 조합하여 높은 정확도를 달성.
- 배깅(Bagging) : Bootstrap Aggregation의 약자로 기존 학습 데이터(Original Data)로부터 랜덤하게 '복원추출'하여 동일한 사이즈의 데이터셋을 여러개 만들어 모델을 여러번 학습시키는 방법.
* 부트스트랩 샘플링(Bootstrap sampling; 복원추출)방법을 사용하여 OOB(Out-Of-Bag)가 발생할 수 있음.
* OOB : 선택받지 못하는 샘플로, OOB가 낮을 수록 오분류율이 낮다고 볼 수 있음
- 부스팅(Boosting): 이전 모델이 잘못 예측한 샘플에 가중치를 부여하여 다음 모델이 이를 보완하는 순차적인 방식으로 학습하는 방법. 약한 학습기들을 결합하여 강한 학습기를 만드는 앙상블 학습 기법.
- 스테킹(Stacking) : 여러 개의 다른 모델(개별 추정기)의 예측 결과를 다음 단계의 새로운 특성으로 사용하여 더 정확한 예측을 수행하는 학습 방법.
▶️ 랜덤 포레스트(Random forest) ?
Leo Breiman이 처음 소개한 랜덤 포레스트 논문
https://link.springer.com/article/10.1023/A:1010933404324
- 앙상블의 배깅 방법을 사용한 모델. 기존 배깅 방법에 변수 임의화를 더한 방법이다.
- 의사결정 트리(나무)의 출력을 결합하여 포레스트(숲)을 만드는 방법.
- 랜덤 포레스트는 변수를 랜덤으로 선택하는 과정을 통해 개별 나무들의 상관성을 줄여 예측력과 안정성을 향상 할 수 있는 장점이 있다.
- 다양한 종류의 데이터에 대해 높은 예측 성능을 보인다. 대규모 데이터에 적합하다.
'프로젝트+스터디' 카테고리의 다른 글
| 파이썬 병렬처리(@BACKGROUND) (2) | 2024.09.25 |
|---|---|
| [논문리뷰] Attention Is All You Need (0) | 2024.04.04 |
| 자연어 처리 챗봇 프로젝트 _ 챗쪽이 (0) | 2024.03.15 |
| AI기반 OCR프로젝트 마지막 - 후처리 알고리즘 (0) | 2024.03.12 |
| AI기반 OCR프로젝트 2 - 모델 선정 및 학습 (0) | 2024.03.12 |


