우선 우리팀이 목표하는 시스템은 도로 위의 과속 단속 카메라를 이용한다는 가정하에, 실시간으로 과적차량을 감지하고 기록해주는 시스템이었다. YOLOv5로 영상 탐지를 테스트 해보았을 때, 영상을 집어넣으면 해당 영상의 frame을 모두 스캔한 뒤 영상이 통째로 저장되는 것을 확인할 수 있었다.
당시 cv를 배운 후라 '내 생각에는' cv2.VideoCapture를 통해 비디오를 먼저 연결해서 열고,
ret, frame = video.read()를 통해 불러온 frame을 하나씩 모델에 넣어주고 결과를 출력해주는 것을 반복하면
실시간으로 감지와 기록처리를 할 수 있지 않을까 생각이 들었다. (역시 배운 것에 답이 있다!)
그래서, 영상을 '실시간'으로 모델에 넣고 출력하는 부분의 서버 구축은 내가 진행해보기로 했다.
영상을 실시간으로 frame으로 나눠 모델에 넣는 부분은 생각한데로 순조롭게 진행되었지만, 오히려 가장 힘들었던 부분은 모델을 가져오는 부분과, 결과(prediction)에서 예측된 바운딩 박스(bbox)의 좌표를 뽑는 것이었다....ㅠㅠ
(1)
우선 모델을 불러오는 것은 처음엔 단순히 model = torch.hub.load('ultralytics/yolov5', 'custom', 'best.pt') 코드를 통해 로드하려고 했다. 하지만 Yolo 모델 학습 시 리눅스 명령어를 사용해서, 서버를 구축할 때 윈도우 환경에서 인식하지 못하는 문제가 발생했다. 내가 컴퓨터 운영체제에 대한 지식이 부족해서 힘든 오류였을 수 있지만...ㅎㅎ pathlib 오류 코드를 통해https://github.com/ultralytics/yolov5/issues/11330 페이지에서 해결 코드를 찾았고,
두 번째로 prediction에서 바운딩 박스의 좌표가 제대로 찍히지 않아 어려움을 겪었다. 우선 prediction의 정확한 형태를 알지 못해 혼란을 겪었고, 두 번째로 모델에 넣기전 frame을 전처리 해준 것이 결과값에 영향을 줘 인터넷을 search해가며 찾아본 코드들이 내 결과값과 달라 더 혼란을 겪었다.
prediction을 직접 찍어보고 __dir__() 메서드와 데이터 프레임을 이용해서 결과값을 정확한 속성을 찾아보면서 결국 바운딩 박스가 쳐진 결과값을 실시간으로 출력하는 코드를 만들었다.
import cv2
import torch
import os
import time
import pathlib
temp = pathlib.PosixPath
pathlib.PosixPath = pathlib.WindowsPath
# custom/local model
model = torch.hub.load('ultralytics/yolov5', 'custom', 'best.pt')
overload_folder = "overload"
if not os.path.exists(overload_folder):
os.makedirs(overload_folder)
def get_stream_video(query):
# camera 정의
video = cv2.VideoCapture(f'./videos/{query}')
while (video.isOpened()):
ret, frame = video.read()
if ret:
# 모델 돌리기
with torch.no_grad():
prediction = model(frame)
annotated_image = visualize_prediction(frame, prediction)
success, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
yield (b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n' +
bytearray(frame) + b'\r\n')
def visualize_prediction(image, prediction):
cord = prediction.xyxy[0]
name = prediction.names
size = len(cord)
for i in range(size - 1):
XMin, YMin, XMax, YMax, conf, cls = cord[i, :6]
# 과적이 아닌 차량은 박스 출력X
if int(cls) == 0:
if conf > 0.85: # 신뢰도가 일정 수준 이상인 객체만 표시
cv2.rectangle(image, (int(XMin), int(YMin)), (int(XMax), int(YMax)), (0, 0, 255), 2)
cv2.putText(image, f'Overload:{conf:.2f}', (int(XMin), int(YMin) - 10), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 255), 2, cv2.LINE_AA)
print(f"{name[int(cls)]} cord:", cord[i, :5])
return image
2. 후처리 알고리즘
과적 차량을 인식하면 해당 차량의 번호판 위치를 인식하기 위해 다음 모델에 해당 frame을 보낸다. 이때, 번호판 위치를 읽어내지 못하거나, 사진이 흔들려 OCR로 번호를 정확히 읽어오지 못할 경우에 대비해서 같은 차량에 대한 frame을 여러개 저장하고, 같은 차량에 대한 frame만 모아서 기록을 만들어야 했다. (혹시 OCR이 정확한 결과를 출력하지 못할 경우에 대비해 사용자가 직접 저장된 사진을 보고 번호를 볼 수 있게 하고싶었다.)
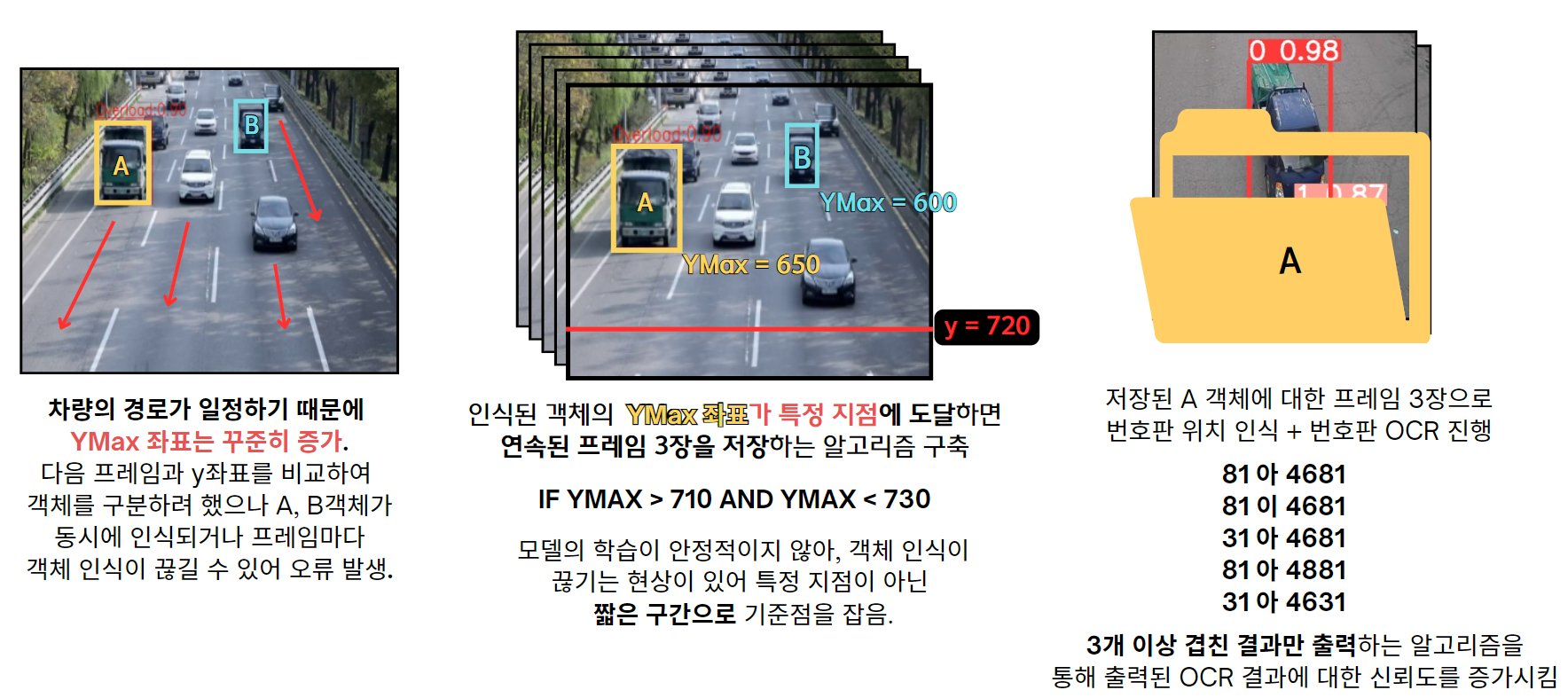
문제는 과적차량으로 인식된 객체가 프레임이 달라지면 동일한 객체로 인지되지 못한다는 것이다.
이에 대해 조장을 포함한 다른 조원들이 다양한 알고리즘 아이디어를 냈다. 그 중 가장 마지막까지 조원들이 집중했던 아이디어는 bbox의 center값을 이용하여 다음 frame에서 center값이 bbox 영역안에 있다면 동일한 객체로 보자는 의견이었다. 하지만 나는 아직 모델이 안정적이지 않아서 frame마다 일정하게 객체를 인식하지 못하고 순간순간 객체 인식이 끊기거나,한 프레임 안에서 두,세 개의 객체를 동시에 인식하기도 했기 때문에 해당 알고리즘의 위험도와 계산의 복잡성이 너무 높아진다고 생각했다.
그래서 내가 구상한 알고리즘은 차량의 일정한 이동 방향과 YMAX값을 이용한 알고리즘이다.
프레임 안에서 특정 구간의 차량 움직임은 한 방향으로 일정하다. 과속 단속 CCTV에 과적 단속까지 합쳐진다는 가정하에, 탐지되는 객체의 움직임은 프레임이 진행될 수록 YMax 값이 증가하는 모습이다.
따라서 YMAX 좌표를 이용해 동일한 객체의 프레임을 여러장 저장하는 알고리즘을 구현했다.
특정 지점에서 객체가 탐지되면 해당 프레임부터 연속된 5장의 프레임을 저장한다. 원래는 특정 지점으로 기준점을 잡으면 좋겠지만, 모델이 안정적이지 않아 감지된 객체를 놓칠 위험이 있어 한 지점이 아닌 특정 구간으로 기준점을 잡았다. 동시에 두 객체가 인식되는 상황을 방지하기 위해 한 프레임당 좌표 움직임을 참고하여(한 프레임당 대략 5~7픽셀 정도 움직이는 것을 확인) 그 구간을 20픽셀 정도로 짧게 지정하였습니다.
그렇게 저장된 프레임 묶음은 다음 번호판 인식 모델과 OCR 인식으로 보내져 번호판 위치와 숫자+한글을 인식했다. 5개의 출력 결과 중 3개 이상 동일하게 나온 결과를 출력함으로써 출력값에 대한 신뢰도를 높혔다.
download = False
cnt = 0
current_time = 0
current_folder = None
def visualize_prediction(image, prediction):
global download, cnt, current_folder, current_time
cord = prediction.xyxy[0]
name = prediction.names
size = len(cord)
for i in range(size - 1):
XMin, YMin, XMax, YMax, conf, cls = cord[i, :6]
# print(XMin, YMin, XMax, YMax)
# print(f"{name[int(cls)]} cord:", cord[i, :5])
if int(cls) == 0:
if conf > 0.85: # 신뢰도가 일정 수준 이상인 객체만 표시
cv2.rectangle(image, (int(XMin), int(YMin)), (int(XMax), int(YMax)), (0, 0, 255), 2)
cv2.putText(image, f'Overload:{conf:.2f}', (int(XMin), int(YMin) - 10), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 255), 2, cv2.LINE_AA)
print(f"{name[int(cls)]} cord:", cord[i, :5])
if not download:
if YMax > 710 and YMax < 730:
download = True
# 한 객체 폴더 생성
current_time = time.strftime('%Y-%m-%d_%H-%M-%S', time.localtime())[5:]
current_folder = os.path.join(overload_folder, current_time)
if not os.path.exists(current_folder):
os.makedirs(current_folder)
# 이미지 저장
print('다운로드 시작')
cv2.imwrite(os.path.join(current_folder, f"{current_time}_{cnt}.jpg"), image)
cnt += 1
# 이미지 저장
if download:
cv2.imwrite(os.path.join(current_folder, f"{current_time}_{cnt}.jpg"), image)
cnt += 1
print('다운로드')
# 5장 저장하면 stop
if cnt == 3:
download = False
cnt = 0
print('다운로드 끝')
return image
결과적으로 시연한 영상이다. CPU로 돌려서 영상의 끊김이 있었지만, GPU로 돌릴 경우 영상의 끊김없이 훨씬 매끄러운 출력이 가능했다.
이번 프로젝트를 통해 Vision AI에 대한 열정이 더욱 높아졌고, 직접 시스템과 알고리즘 코드를 구현하는 데 있어서 큰 발전을 이룬 것 같습니다. 앞으로는 배운 기술을 활용하여 더욱 의미 있고 실용적인 시스템을 구현하고싶습니다.