1. 셀레니움
셀레니움(Selenium)은 웹 애플리케이션을 자동화하기 위한 프레임워크입니다. 주로 웹 브라우저를 제어하고 웹 페이지 상의 작업을 자동으로 수행하는 데 사용됩니다.
설치 !pip install selenium !pip install chromedriver_autoinstaller
셀레니움은 브라우저를 컨트롤 하는 명령어가 있는 라이브러리이고, ChromeDriver는 Selenium이 웹 브라우저를 제어할 때 사용되는 드라이버로, Selenium WebDriver와 브라우저 간의 통신을 담당합니다.
2. 네이버 웹툰 댓글 가져와보기.

네이버에 댓글을 보면 Best댓글과 전체댓글이 나누어져있습니다. 하지만 전체댓글을 클릭해도 URL에는 변화가 없습니다.
따라서 Request로 해당 주소를 요청해서 내용을 가져오면 BEST댓글만 가져올 수 있고 전체댓글의 내용은 가져와지지 않습니다. 이럴떄 셀레니움을 이용해서 웹 브라우저를 제어하여 전체댓글이라는 버튼을 클릭해서 페이지를 자동으로 넘길 수 있습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://comic.naver.com/webtoon/detail?titleId=769209&no=96&week=wed')
soup = BeautifulSoup(driver.page_source)
comment_area = soup.findAll('span',{'class','u_cbox_contents'})
# print(comment_area)
print('********** 베스트 댓글 **********')
for i in range(len(comment_area)):
comment = comment_area[i].text.strip()
print(comment)
print('-'*30)우선 기존에 크롤링의 방식과 동일하게 베스트 댓글을 가져옵니다.
driver.find_element('xpath','/html/body/div[1]/div[5]/div/div/div[5]/div[1]/div[3]/div/div/div[4]/div[1]/div/ul/li[2]/a/span[2]').click()위에 코드가 바로 전체댓글을 클릭하는 명령어 입니다. 전체댓글 버튼의 xpath를 통해 요소를 찾아내고, click()함수로 해당 요소를 클릭해주었습니다.
XPath는 컴퓨터 파일 시스템에서 사용하는 경로 표현식과 유사한 경로 언어입니다.
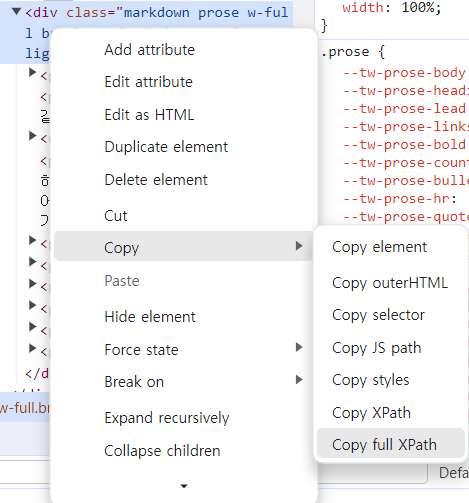
원하는 요소에서 마우스 우클릭을 하고 copy에 가면 XPath의 full 경로를 복사해올 수 있습니다. 방법이 아주 쉽기때문에 웹 페이지에서 특정 요소를 찾는 데 자주 활용됩니다.
soup = BeautifulSoup(driver.page_source)
comment_area = soup.findAll('span',{'class','u_cbox_contents'})
print(comment_area)
print('********** 전체 댓글 **********')
for i in range(len(comment_area)):
comment = comment_area[i].text.strip()
print(comment)
print('-'*30)전체 댓글을 클릭 한 후에 다시 댓글창 부분의 정보를 print해보면 전체 댓글의 내용을 가져올 수 있습니다.
3. 픽사베이에서 여러개 이미지 가져오기.
import chromedriver_autoinstaller
import time
from selenium import webdriver
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url = 'https://pixabay.com/ko/images/search/너구리/'
driver.get(url)
time.sleep(3)
# 브라우저 페이지가 모두 준비될 때까지 3초 기다려줌image_area_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div'
image_area = driver.find_element(By.XPATH, image_area_xpath)
image_elements = image_area.find_elements(By.TAG_NAME, 'img')from selenium.webdriver.common.by import By 를 통해서 (By.TAG_NAME, 'img') 와 같은 쉬운 방법으로 요소를 찾을 수 있습니다. By.TAG_NAME 은 태그네임으로 찾겠다는 의미이고, 뒤에 찾을 태그 'img'를 붙여줍니다. find_elements를 통해 img 태그인 요소를 모두 찾아옵니다.
# for문을 돌면서 각 요소의 src 속성내용만 가져오기.
image_urls = []
for image_element in image_elements:
image_url = image_element.get_attribute('data-lazy-src')
if image_url is None:
image_url = image_element.get_attribute('src')
print(image_url)
image_urls.append(image_url)from urllib import parse
import os
for i in range(len(image_urls)):
image_url = image_urls[i]
url = parse.urlparse(image_url)
name, ext = os.path.splitext(url.path)
image_byte = Request(image_url, headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'})
f = open(f'raccoon{i}.{ext}', 'wb')
f.write(urlopen(image_byte).read())
f.close()urllib.parse 모듈을 사용하여 이미지 URL을 파싱합니다. 이로써 URL의 구성 요소를 추출할 수 있습니다. os.path.splitext() 함수를 사용하여 파일 경로에서 이름과 확장자를 분리합니다.
image_byte = Request(image_url, headers = {}) 에서는 이미지 URL에 대한 HTTP 요청을 생성하고있습니다. 이때, 사용자 에이전트 헤더를 추가하여 웹 서버에게 브라우저처럼 보이도록 설정하는 이유는 해당 사이트에서 브라우저 요청이 아니면 해당 이미지를 띄우지 않고 무조건 다운로드를 하도록 응답하기 때문입니다.
f = open(f'raccoon{i}.{ext}', 'wb')에서는 이미지를 저장할 파일을 바이너리 쓰기 모드로 엽니다. 파일 이름은 'raccoon' 다음에 인덱스 i와 확장자 ext를 추가하여 고유한 이름을 생성합니다.
f.write(urlopen(image_byte).read())에서는 이미지 데이터를 HTTP 응답에서 읽어와서 파일에 기록합니다. urlopen() 함수를 사용하여 HTTP 요청을 보내고, read() 메서드를 사용하여 응답 데이터를 읽습니다.
