
[논문] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
introduce
최근에 제안된 신경 기계 번역 모델들은 대부분 인코더-디코더 방식을 사용합니다. 이 방식은 소스 문장을 고정 길이 벡터로 인코딩하고, 디코더를 통해 번역을 생성합니다. 그러나 고정 길이 벡터는 문장의 특성을 담을 수 있는 양동이로 생각할 수 있습니다. 문장의 크기가 길어지면 양동이에 모든 정보를 담기 어렵고, 기울기 소실 문제가 발생할 수 있습니다. 이 논문은 모델이 목표 단어와 관련이 큰 부분을 찾아 고정 길이 벡터의 한계를 극복하도록 제안합니다. 이렇게 하면 중요한 단어를 양동이에 우선적으로 담을 수 있어 문장의 의미가 보다 명확해집니다.
신경 기계 번역: 최근에 제안된 신경 기계 번역은 문장을 읽고 올바른 번역을 출력하는 단일 대형 신경망을 사용합니다. 각 언어에 대해 하나의 인코더와 디코더가 있거나, 문장별로 적용되는 언어별 인코더가 포함될 수 있습니다. 인코더 신경망은 소스 문장을 읽고 고정 길이 벡터로 인코딩하며, 디코더는 인코딩된 벡터에서 번역을 출력합니다. 이 시스템은 주어진 소스 문장에 대해 올바른 번역의 확률을 최대화하기 위해 공동으로 학습됩니다. 인코딩된 벡터 안에는 입력 문장의 의미적 정보, 문맥 정보, 길이와 순서 등의 요약된 정보가 담겨있습니다. 그러나 제한된 크기의 벡터는 모든 세부 정보를 완벽하게 담기 어렵고 정보 손실이 발생할 수 있습니다.
인코더-디코더 방식의 문제점: 인코더-디코더 접근 방식의 잠재적인 문제는 신경망이 소스 문장의 모든 필요한 정보를 고정 길이 벡터로 압축해야 한다는 것입니다. 이는 특히 긴 문장의 처리에 어려움을 줄 수 있습니다. 이 논문은 정렬을 함께 학습하고 번역을 실행하는 것이 기본 인코더-디코더 방식보다 훨씬 향상된 성능을 보여줍니다. 특히 질적 분석에서는 제안된 모델이 소스 문장과 타겟 문장 사이의 언어적으로 더욱 일치하는 정렬을 보여줍니다.
background : Neural Machine Translation
번역은 주어진 소스 문장(x)에 대한 조건부 확률(y)를 최대화하여 목표 문장(y)을 찾는 과정입니다. 신경 기계 번역에서는 병렬 훈련 말뭉치를 사용하여 모델의 매개변수를 조절하여 문장 조합의 조건부 확률을 극대화하는 학습을 진행합니다. 번역 모델이 조건부 분포를 학습한 후에는 소스 문장에 대해 가장 적합한 번역을 생성할 수 있습니다. 신경 기계 번역은 일반적으로 인코딩과 디코딩 두 가지 요소로 구성됩니다. 인코딩은 소스 문장(x)을 처리하여 벡터로 표현하는 과정이고, 디코딩은 해당 벡터를 변수 길이의 대상 문장(y)으로 변환하는 과정입니다.
신경 기계 번역은 이미 유망한 결과를 보여주고 있으며, 기존의 번역 시스템에 신경 구성 요소를 추가하는 방식으로 이전 수준의 최고 성능을 넘어설 수 있습니다. 예를 들어, 구절 쌍에 점수를 매기거나 번역 후보의 순위를 재조정하는 방법을 사용할 수 있습니다.
LSTM과 Attention 모델은 번역에 사용되는 두 가지 다른 구조입니다. LSTM은 은닉 상태(hidden state)와 셀 상태(cell state)라는 값을 사용하여 복잡한 식으로 은닉 상태를 계산합니다. LSTM은 주로 시퀀스 데이터의 장기 의존성을 학습하는 데 사용되며, Seq2Seq 구조에서 입력과 출력 사이의 변환에 주로 사용됩니다.
Seq2Seq 모델은 RNN 또는 LSTM을 사용하여 입력 시퀀스를 처리하고, 마지막 은닉 상태를 디코더의 초기 상태로 사용하여 입력 시퀀스를 고정된 길이의 벡터로 압축합니다.
반면, Attention을 사용한 Seq2Seq 모델은 디코더가 출력을 생성하는 동안 인코더의 모든 입력 위치에 주의를 기울일 수 있도록 하는 메커니즘입니다. 디코더의 각 단계에서 어텐션은 현재의 디코더 상태에 따라 인코더의 각 입력 위치에 가중치를 할당하고, 이 가중치가 곱해진 인코더 출력은 컨텍스트 벡터로 취합되어 디코더의 입력으로 사용됩니다.
요약하자면, 번역은 주어진 소스 문장과 대상 문장 간의 조건부 확률을 최대화하여 번역 결과를 생성하는 것이며, 신경 기계 번역은 이를 위해 인코딩과 디코딩을 사용하는 구조입니다. LSTM과 Attention은 번역에 사용되는 두 가지 다른 모델 구조로, 각각 시퀀스 데이터의 장기 의존성을 학습하고 인코더-디코더 간의 상호작용을 강화합니다.
RNN ENCODER–DECODER
인코더-디코더 프레임워크에서, 인코더는 입력 문장을 벡터로 변환하는 역할을 합니다. 일반적으로 RNN(순환 신경망)을 사용하는데, Sutskever 등(2014)은 LSTM(Long Short-Term Memory)을 이용했습니다.
디코더는 주로 컨텍스트 벡터와 이전에 예측된 단어들을 사용하여 다음 단어를 예측하는데 사용됩니다. 다시 말해, 디코더는 조건부 확률을 이용하여 번역 결과인 y에 대한 확률을 정의합니다. 이 과정에서 비선형 함수 g가 사용되며, 여러 층으로 구성될 수 있습니다. 그리고 디코더는 이 함수를 통해 각 단어의 확률을 출력합니다.
요약하자면, 인코더는 입력 문장을 벡터로 변환하고, 디코더는 컨텍스트 벡터와 이전 예측 단어들을 사용하여 다음 단어를 예측합니다. 이를 통해 번역 결과에 대한 확률을 계산합니다.
DECODER: GENERAL DESCRIPTION
새로운 모델 아키텍처에서는 인코더-디코더 접근법과는 다른 방식을 사용합니다. 이 모델에서는 목표 단어 yi의 확률이 독립적인 컨텍스트 벡터 ci에 의해 결정됩니다. 컨텍스트 벡터 ci는 인코더가 입력 문장에 대해 만든 주석(h1, · · · , hTx)에 의존합니다. 각 주석 hi는 전체 입력 시퀀스에 대한 정보를 담고 있으며, i번째 단어의 주변 부분에도 집중합니다. 각 주석 hi의 가중치 αij는 위치 j 주변의 입력과 위치 i에서의 출력이 얼마나 일치하는지를 평가하는 점수입니다. 컨텍스트 벡터 ci는 이러한 주석 hi의 가중 합으로 계산됩니다.
"alignment model"은 어텐션 메커니즘을 표현하는 모델입니다. 이 모델은 주어진 문장에서 다음 단어를 예측하는 동안, 입력 문장의 특정 부분에 집중하거나 정렬하는 정도를 결정하는 "alignment"을 사용합니다. 이것이 어텐션 메커니즘의 핵심 아이디어입니다.
전통적인 기계 번역과는 달리, 어텐션은 잠재 변수로 간주되지 않습니다. 대신, 어텐션 모델은 소프트맥스 함수를 사용하여 정규화된 어텐션 가중치를 직접 계산합니다. αij는 타겟 단어 yi가 소스 단어 xj에 대해 번역되거나 정렬될 확률을 나타내며, ci는 이러한 확률을 기반으로 모든 주석들에 대한 기대값입니다.
간단히 말해서, 이것은 디코더에서 어텐션 메커니즘을 구현한 것입니다. 디코더는 소스 문장의 일부에 얼마나 주의를 기울일지를 결정합니다. 주의 메커니즘을 사용함으로써, 인코더는 문장의 모든 정보를 고정 길이의 벡터로 인코딩하는 부담에서 벗어날 수 있습니다. 이 새로운 접근 방식을 통해 정보는 주석들을 통해 분산되어 필요에 따라 디코더에서 선택적으로 검색됩니다.
ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
제안된 체계에서는 양방향 RNN을 사용하여 주석을 단어의 이전 및 다음 단어들과 함께 요약하는 방법을 제안합니다. 이를 위해 순방향 RNN과 역방향 RNN을 결합하여 사용합니다. 순방향 RNN은 입력 시퀀스를 순서대로 읽어 순방향 은닉상태를 계산하고, 역방향 RNN은 입력 시퀀스를 역순으로 읽어 역방향 은닉상태를 계산합니다.
각 단어에 대한 주석은 순방향 은닉상태와 역방향 은닉상태를 연결하여 얻습니다. 즉, 주석은 [순방향 은닉상태; 역방향 은닉상태]로 표현됩니다. 이렇게 함으로써 주석은 이전 단어와 다음 단어의 요약을 포함하게 됩니다. RNN은 최근 입력에 더 잘 대응하는 경향이 있으므로, 주석은 해당 단어의 주변 단어에 주로 초점을 맞출 것입니다. 이러한 주석들은 나중에 디코더 및 어텐션 모델에서 컨텍스트 벡터를 계산하는 데 사용됩니다.


EXPERIMENT SETTINGS
영어에서 프랑스어로의 번역 작업으로 평가합니다. 양방향 병렬 말뭉치(영어, 프랑스어)를 사용하고 비교를 위해 최근에 제안된 RNN 인코더-디코더의 성능도 보고합니다. 두 모델 모두 동일한 교육 절차와 데이터 세트를 사용합니다.
DATASET
WMT '14에 있는 850M개 단어의 영어-프랑스어 병렬 말뭉치를 348M개 크기로 축소하여 사용했습니다. 일반적인 토큰화 이후에는 각 언어의 30,000개의 가장 빈번한 단어로 모델을 교육합니다. 단어 목록에 포함되지 않은 모든 단어는 특수 토큰([UNK])으로 매핑됩니다. 데이터에는 소문자 변환 또는 어간 추출과 같은 다른 특수 전처리를 적용하지 않습니다.
MODELS
두 가지 유형의 모델을 훈련합니다. 첫 번째는 RNN 인코더-디코더이며, 다른 하나는 제안된 모델로 RNNsearch를 참조합니다. 각 모델을 두 번 훈련합니다. 먼저 문장 길이가 30 단어까지인 경우(RNNencdec-30, RNNsearch-30), 그런 다음 문장 길이가 50 단어까지인 경우(RNNencdec-50, RNNsearch-50)로 나누어 훈련합니다.
RNNencdec의 인코더와 디코더는 각각 1000개의 은닉 유닛을 가지고 있습니다. RNNsearch의 인코더는 1000개의 은닉 유닛을 갖는 각각의 정방향 및 역방향 순환 신경망(RNN)으로 구성됩니다. 디코더는 1000개의 은닉 유닛을 가지고 있습니다. 양쪽 모델에서는 각 타겟 단어의 조건부 확률을 계산하기 위해 하나의 맥스아웃 은닉 층을 가진 다층 네트워크를 사용합니다.
("Single maxout layer"는 일반적으로 딥러닝 모델의 hidden layer 중 하나를 가리키는 용어입니다. Maxout은 비선형 활성화 함수로서, 입력 값 중 최댓값을 선택하여 출력하는 방식을 사용합니다.)
각 모델을 훈련하기 위해 미니배치 확률적 경사 하강 (SGD) 알고리즘과 Adadelta (Zeiler, 2012)를 함께 사용합니다. 각 모델을 약 5일 동안 훈련했습니다. 모델이 훈련되면 빔 서치를 사용하여 조건부 확률을 대략적으로 최대화하는 번역을 찾습니다.
QUANTITATIVE RESULTS

RNNsearch-50*은 개발 세트에서의 성능이 향상되지 않을 때까지 훈련이 훨씬 길게 이루어졌습니다.
표 1에서는 BLEU 점수로 측정된 번역 성능을 나열하였습니다. 표에서 명확하게 확인할 수 있듯이 모든 경우에서 제안된 RNNsearch가 기존의 RNNencdec보다 우수한 성능을 보입니다. 더 중요한 것은 RNNsearch의 성능이 알려진 단어로 이루어진 문장만을 고려할 때 기존 구문 기반 번역 시스템(Moses)과 동등한 수준임을 보여줍니다. 이는 Moses가 RNNsearch와 RNNencdec를 훈련시키는 데 사용한 병렬 말뭉치에 추가로 별도의 단일 언어 말뭉치(418M 단어)를 사용한다는 고려 사항을 고려할 때 매우 중요한 성과입니다.
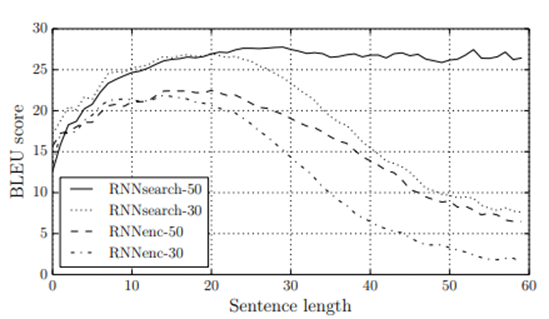
제안된 방법의 동기 중 하나는 기본 인코더-디코더 접근법에서 고정 길이의 컨텍스트 벡터를 사용한다는 것이었습니다. 우리는 이 제한 때문에 기본 인코더-디코더 접근법이 긴 문장에서 성능이 저하될 수 있다고 추측했습니다. 그림 2에서 볼 수 있듯이, RNNencdec의 성능은 문장의 길이가 증가함에 따라 급격하게 하락합니다. 반면에 RNNsearch-30 및 RNNsearch-50은 문장의 길이에 대해 더 견고합니다. 특히 RNNsearch-50은 50 단어 이상의 문장에서도 성능 저하가 없습니다. 제안된 모델이 기본 인코더-디코더보다 뛰어나다는 것은 RNNsearch-30이 심지어 Table 1에서 RNNencdec-50을 능가한다는 사실로 더욱 확인됩니다.
ALIGNMENT
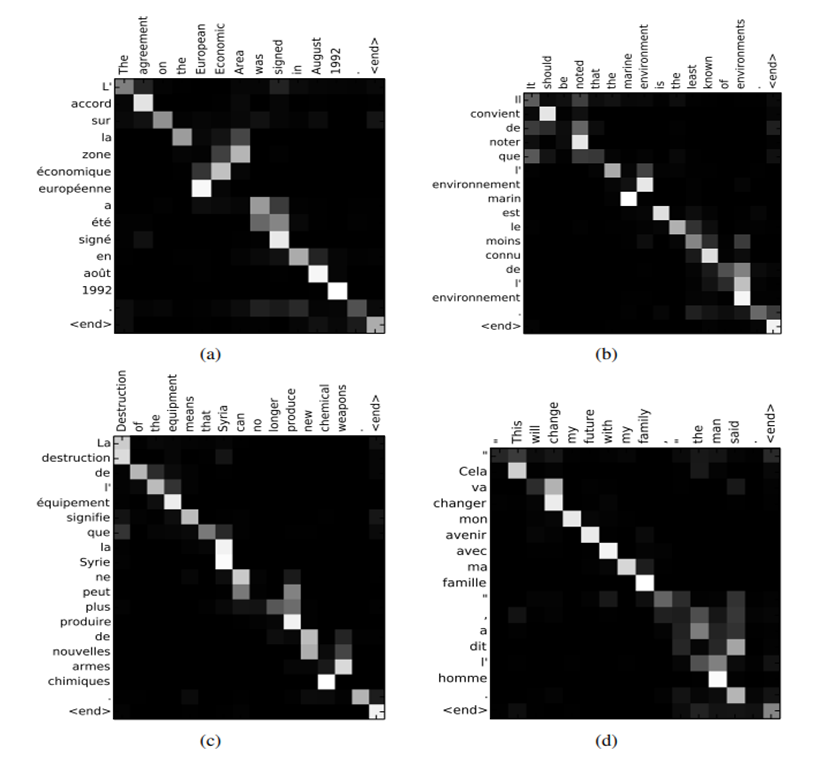
주석 가중치 αij를 회색조로 표시합니다. (0은 검은색, 1은 흰색입니다.) 제안된 방법은 생성된 번역과 원본 문장 사이의 (소프트) 매핑을 직관적으로 확인하는 방법을 제공합니다. 이를 위해 Eq. (6)의 주석 가중치 αij를 시각화하여 수행됩니다. (그림 3을 참조하세요.) 각 플롯의 행은 주석과 관련된 가중치를 나타냅니다. 이를 통해 대상 단어를 생성할 때 원본 문장에서 어떤 위치가 더 중요하게 간주되었는지 알 수 있습니다.
그림 3의 정렬에서는 영어와 프랑스어 단어 간의 정렬이 대체로 단조롭다는 것을 알 수 있습니다. 각 행렬의 대각선을 따라 강한 가중치를 볼 수 있습니다. 그러나 일부 비단조적이고 비단조적인 정렬도 관찰됩니다. 형용사와 명사는 일반적으로 프랑스어와 영어 사이에서 서로 다르게 정렬되며, 그림 3 (a)에서 확인할 수 있습니다. 이 그림에서 모델은 "[European Economic Area]"를 "[zone économique européenne]"로 올바르게 번역합니다. RNNsearch는 "[zone]"을 "[Area]"에 올바르게 정렬하고, "[European]" 및 "[Economic]"은 건너뛰고, 그런 다음 한 단어씩 돌아가며 전체 구문 "[zone économique européenne]"을 완성합니다.
소프트 매핑의 강점은 특히 그림 3 (d)에서 분명합니다. "[the man]"이 "[l'homme]"으로 번역된 소스 구문을 고려해 봅시다. 어떤 하드 매핑도 "[the]"를 "[l']"에, "[man]"을 "[homme]"에 매핑하지 못합니다. 왜냐하면 "[the]" 다음에 오는 단어를 고려해야 하기 때문에 "[le]", "[la]", "[les]" 또는 "[l']"로 번역해야 할지 결정해야 합니다. 소프트 매핑은 모델이 "[the]"와 "[man]"을 모두 살펴보도록 자연스럽게 이 문제를 해결합니다. 이 예에서 모델은 "[the]"를 "[l']"로 올바르게 번역할 수 있었습니다. 소프트 매핑의 추가적인 이점은 일부 단어를 어디에서도 매핑하지 않고도 자연스럽게 서로 다른 길이의 소스 및 대상 구문을 처리할 수 있다는 것입니다. ([NULL]을 사용하지 않아도 됨).
그림 2에서 명확히 확인할 수 있듯이 제안된 모델인 RNNsearch는 기존 모델인 RNNencdec보다 긴 문장을 번역하는 데 훨씬 뛰어납니다. 이는 RNNsearch가 긴 문장을 완벽하게 고정 길이 벡터로 인코딩할 필요가 없고, 특정 단어를 중심으로 입력 문장의 부분을 정확하게 인코딩하면 되기 때문일 것으로 예상됩니다.
RELATED WORK
최근에 손글씨 합성의 맥락에서 Graves (2013)이 제안한 접근 방식과 유사한 방법이 있습니다. Graves의 연구에서는 가우시안 커널의 혼합을 사용하여 주석의 가중치를 계산했는데, 이때 각 커널의 위치, 너비, 혼합 계수는 정렬 모델에서 예측되었습니다. 하지만 우리의 방법과의 주된 차이점은 Graves의 연구에서 주석의 가중치의 모드가 한 방향으로만 이동한다는 것입니다. 기계 번역에서는 문법적으로 올바른 번역을 생성하기 위해 문장의 재배치가 종종 필요합니다. 반면, 우리의 방법은 한 단어를 번역할 때마다 소스 문장에 있는 모든 단어에 대해 주석 가중치를 계산합니다.
Bengio et al. (2003) 이후로 신경망은 기계 번역에서 널리 사용되어 왔습니다. 그러나 신경망은 주로 기존의 통계 기계 번역 시스템에 단일 기능을 제공하거나 기존 시스템에서 제공하는 후보 번역 목록을 다시 순위 매기는 데 사용되었습니다.
예를 들어, Schwenk (2012)는 피드포워드 신경망을 사용하여 소스 및 대상 구문 쌍의 점수를 계산하고, 이 점수를 구문 기반 통계 기계 번역 시스템의 추가 기능으로 제안했습니다. 그리고 Kalchbrenner와 Blunsom (2013) 및 Devlin 등 (2014)은 신경망을 기존 번역 시스템의 하위 구성 요소로 사용하여 성공적인 결과를 얻었습니다.
기존의 접근 방식은 번역 성능을 향상시킬 수 있는 것으로 나타났지만, 우리는 신경망을 기반으로 한 완전히 새로운 번역 시스템을 설계하는 것에 관심이 있습니다. 이 논문에서 고려하는 신경 기계 번역 접근 방식은 이전의 작업과 근본적으로 다릅니다. 우리의 모델은 기존 시스템의 일부로서 신경망을 사용하는 대신 독립적으로 작동하며 소스 문장에서 직접 번역을 생성합니다.
'AI' 카테고리의 다른 글
| [논문 리뷰] BPE Tokenizer (1) | 2024.02.04 |
|---|---|
| KLUE (0) | 2024.02.02 |
| 워드 임베딩 시각화 (0) | 2024.01.31 |
| 임베딩 (0) | 2024.01.24 |
| 데이터 전처리 실습 (0) | 2024.01.19 |



